
Edge computing is dead, long live micro clouds and IoT gateways

Valentin Viennot
on 16 November 2020
Tags: edge , Edge Computing , Internet of things , IOT Gateway , microcloud
“The King is dead, long live the King.” It might be my french roots speaking, but it seems that actual use cases are replacing King Edge, and it might be for the best. Warning; do not read this blog if you’re particularly sensitive about edge computing (and if you don’t know what this is about, read the “What’s the deal with edge computing?” blog first).
Is edge computing dead?
As a concept, it probably is. “Edge is the new cloud,” said Forrester, dedicating a whole section of its “tech predictions for 2021” report to edge computing. It certainly is the new cloud trend you should be watching, yet it doesn’t mean much: it is too vague. Let’s rephrase it more kindly; the term edge computing isn’t suitable anymore.
How to implement edge computing
Ask two telcos companies what they mean by edge sites. One will tell you they need five sites for an area the size of Texas. The other will tell you twice that amount for small Connecticut (no offense).
Here are a few dimensions where edge computing is particularly… foggy:
- Scalability and flexibility: Is your edge compute going to run the same workload for the rest of time, or will it need to change over it? Is it a fixed-function use case, or will you need to scale capacity?
- I/Os and connectivity: What are your edge interfaces? Edge is where the data from an army of various devices and sensors get collected. It’s also where a plethora of the same or other devices consume this data. Connecting to all these devices typically requires several interfaces and several interface types, including SCADA, EtherCAT, Bluetooth, WiFi, etc.
- Enclosure: Where will your edge compute fit in? A rack? A chassis? A street cabinet? A ruggedised box?
- Physical environment: Where should you deploy your edge compute? An air-cooled, redundant power, redundant network data center? Out in the cold? Inside a smelting factory?
- Management: How much time do you want to spend managing your edge compute? Probably as little as possible, you’re looking for automation, and, please, no truck-roll! All good, in principle. Depending on how scalable you need to be, your automation and management needs will vary widely. Do you need only remote alerts? Or a full-on?
- Redundancy/Resilience: Do you need high availability? Hardware cost, energy consumption, space, and criticality of the workloads or data make redundancy a low “nice to have” in many scenarios.

Where edge computing is used
It might be the only common feature of every edge definition. Edge is far from your maintenance centers, distributed, not easily accessible. Edge is at the fringe of the network, at the base of a cell tower, in a factory, an office block, or at the back of a supermarket; it is everywhere you have devices connected to the network.
For all these reasons, an Edge solution must be a low-touch “zero-ops” solution. Yet, it doesn’t tell you “where edge computing is used,” and that’s because there’s no right answer: it depends.
Towards a better definition: what is edge computing?
There’s a lot of confusion within the same problem space. The whole edge thing is over-hyped and way too undefined. It covers broad areas with vastly different ops requirements. Ultimately, edge computing is two very different things, although emerging simultaneously for similar reasons:
- Micro clouds: small clusters of compute nodes with local storage and networking;
- Internet of Things (IoT) gateways: nodes centralizing IoT devices data at an edge level.
Welcome micro cloud and IoT gateway
What is a micro cloud?
The data center’s success is built on efficient, repeatable, and well-defined operations. Computing at the edge doesn’t mean trashing all this to go back to where we were before. Instead, it means having smaller, managed clouds, decentralized. In other words, micro clouds.
“Micro clouds are a new class of infrastructure for on-demand computing at the edge,” explains the Ubuntu 20.10 announcement. A micro cloud is a small cluster of compute nodes with local storage and networking. One can even have a micro cloud at home, starting with a Raspberry Pi to experiment.

The best practice is to have at least three nodes in a cluster, a threshold for High Availability and Self-Healing capabilities. MicroK8s is an easy way to set-up Kubernetes with such abilities in minutes. Note that, according to the Forrester 2021 tech predictions, “lightweight Kubernetes deployments will end up accounting for 20% of edge orchestration.”
Finally, for OpenStack lovers, MicroStack is the easiest solution to “putting OpenStack at the edge.”
What is an IoT gateway?
Edge computing isn’t only about having micro clouds at the edge of the network. In fact, many use cases connect to another emerging trend: (Industrial) Internet of Things (I)IoT. With the uncontrolled growth of connected devices sending data through the network, handling all this data at a core level isn’t sustainable, nor resilient to inevitable network downtime. Hence, IoT gateways.
An IoT Gateway is a fundamental component of an edge-computing architecture. Its primary function is to centralize IoT devices data at an edge level, filter it (deciding what information is essential), enable visualization, and perform complex analysis. It differs from the IoT devices themselves, taking them at an industrial scale.
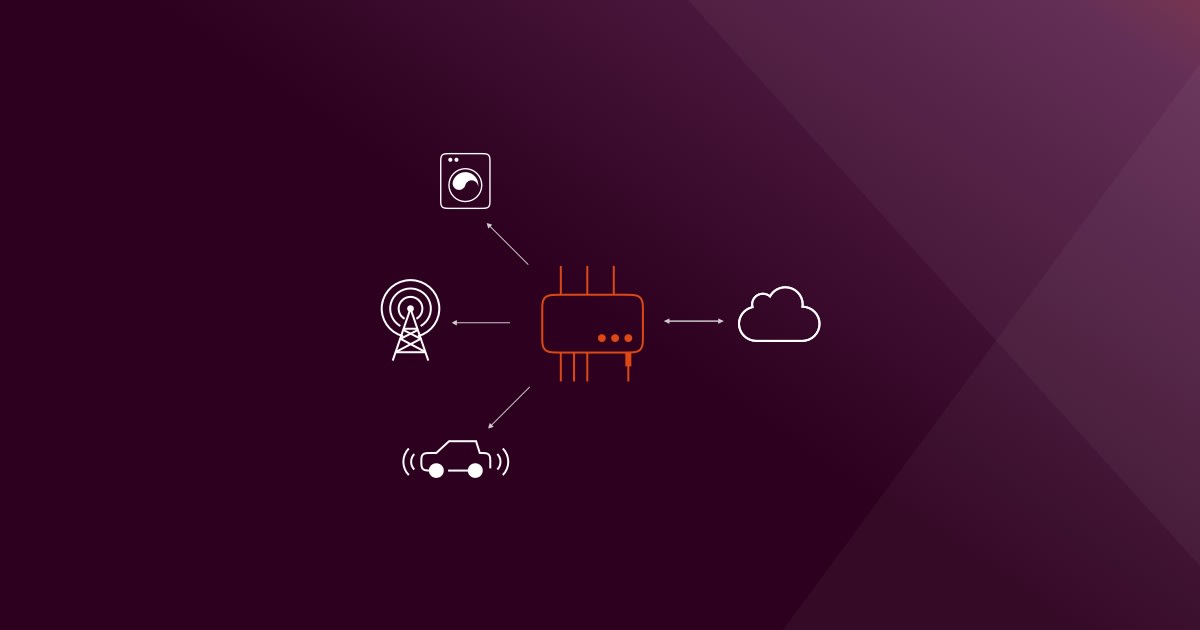
New platforms such as the Nvidia EGX AI platform perform highly complex tasks near to the produced data. With Kubeflow, developing and deploying AI models to edge and IoT has never been simpler. And with Ubuntu Core, the edge-native Linux, it has never been safer.
Outro
Is your use case closer to a micro cloud, a small cluster at the edge, or an IoT gateway, handling data from multiple IoT devices? In both cases, Canonical’s hardened lightweight solutions for industrial applications and production workloads cover it.
Consider experimenting with our solutions today; why not starting with an LXD micro cloud on Raspberry Pi? Learn more about micro clouds on the Ubuntu blog.
Microcloud. Same great performance.
Deploy highly available, secure, and dense microcloud environments anywhere, with a lightweight cloud infrastructure that’s designed for the edge.
Newsletter signup
Related posts
Native integration now available for Pure Storage and Canonical LXD
Canonical, the company behind Ubuntu, and Pure Storage, the IT pioneer delivering enterprise-grade all-flash storage, have partnered to introduce a native...
Simplify security maintenance and compliance with Ubuntu Pro auto-attach for LXD guests
With the latest LXD release, Ubuntu Pro now supports auto-attachment for LXD guest instances, offering organizations a seamless way to extend Ubuntu Pro...
Join Canonical in London at Dell Technologies Forum
Canonical is excited to be partnering with Dell Technologies at the upcoming Dell Technologies Forum – London, taking place on 26th November. This prestigious...