
What is OpenSearch?

Michelle Anne Tabirao
on 1 November 2022
Tags: data , data platform , Database , NoSQL , OpenSearch , Search Technology
OpenSearch is an open-source search and analytics suite. Developers build solutions for search, data observability, data ingestion and more using OpenSearch.
Another popular use case is log analytics. You take the logs from applications, servers and network elements, feed them into OpenSearch, and use the rich search and visualisation functionality to identify issues. For example, a malfunctioning web server might throw a 500 error 0.5% of the time, which can be hard to spot unless you have a real-time graph of all the HTTP status codes the server has thrown in the past twenty-four hours. You can use OpenSearch Dashboards to build these kinds of visualisations from data in OpenSearch.
OpenSearch is offered under the Apache Software Licence, version 2.0, which means it’s free, open source software and maintained by the community. OpenSearch and Dashboards were originally derived from Elasticsearch 7.10.2 and Kibana 7.10.2.
Open source projects frequently come with very active communities. OpenSearch has had over 1.4 million downloads and thousands of stars across the 70+ GitHub repositories. There are 19 open-source associated community projects and OpenSearch has nearly 6 thousand stars on GitHub. The OpenSearch project is also listed in the top 5 search engines in DB engine rankings.
Components of OpenSearch
OpenSearch consists of a data store and search engine called OpenSearch, and a visualisation and user interface called OpenSearch Dashboards. Users can extend the functionality of OpenSearch with a selection of plugins that enhance search, security, performance analysis, machine learning, and more.
Search engine and data store
OpenSearch is a distributed search and analytics engine based on Apache Lucene. After adding data to OpenSearch, it can perform full-text searches on it with all of the features such as search by field, search multiple indices, boost fields, rank results by score, sort results by field, and aggregate results.
OpenSearch can also be used as a NoSQL data store, but this database capability is only secondary, as the database behaviour is mainly implemented so it can perform best-in-class search and analytics functions. This application can add JSON documents to an OpenSearch index, and afterwards offers a persistent storage medium so one can perform a direct search. Furthermore, any tool with an API that reads JSON can also use this data.
One can interact with OpenSearch clusters using the REST API, which offers a great deal of flexibility. For example, clients can use curl or any programming language that can send HTTP requests.
Developers can interact with OpenSearch using the query languages Query DSL, OpenSearch SQL and Piped Processing Language.
Visualisation and user interface
OpenSearch Dashboard is an open-source, integrated visualisation tool that allows users to explore their data in OpenSearch. From real-time application monitoring, threat detection, and incident management to personalised search, OpenSearch Dashboards represent trends, outliers, and patterns in data graphically. The image below shows a sample of data visualisations in the OpenSearch Dashboard.
The Dashboard is built in typescript. Queries can be constructed in the Dashboard using DQL.
Other features and plug-ins
OpenSearch has several features and plugins to help index, secure, monitor, and analyse data. Most OpenSearch plugins have associated OpenSearch Dashboard plugins that provide a convenient, unified user interface.
- Anomaly detection – Identify atypical data and receive automatic notifications
- KNN – Find “nearest neighbours” in your vector data
- Performance Analyzer – Monitor and optimise your cluster
- SQL – Use SQL or a piped processing language to query your data
- Index State Management – Automate index operations
- ML Commons plugin – Train and execute machine-learning models
- Asynchronous search – Run search requests in the background
- Cross-cluster replication – Replicate your data across multiple OpenSearch clusters
OpenSearch Architecture
OpenSearch has a distributed design. This means that users and applications interact with OpenSearch clusters. Each cluster is a collection of one or more nodes running on servers that store your data and process search requests. Of course, OpenSearch can be run locally on a laptop—the system requirements to get started are minimal.
The figure below is an example of an OpenSearch cluster, and shows OpenSearch nodes, OpenSearch Dashboard and data sources.
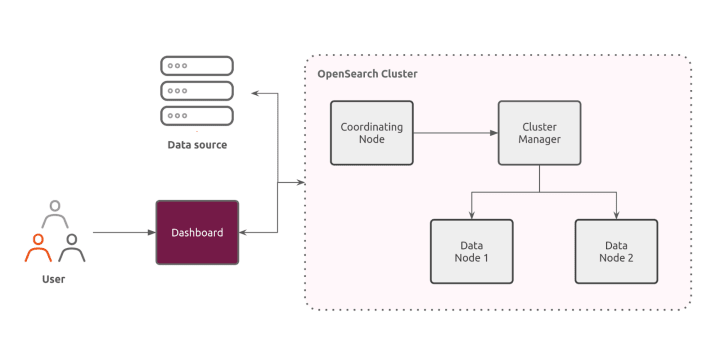
End users can interact directly with the OpenSearch Dashboard, for example to perform data analysis tasks in order to improve business processes. However, before users can access the Dashboard, data sources need to be ingested into the OpenSearch cluster. This data source can be in different formats like log files, metrics, JSON documents, etc.
A cluster can contain various types of nodes: main, coordinating and data nodes. Each node has a different role
- Cluster managers – Manage the overall operation of a cluster and keep track of the cluster state. This includes creating and deleting indexes, keeping track of the nodes that join and leave the cluster, checking the health of each node in the cluster (by running ping requests), and allocating shards to nodes.
- Data nodes – Store and search data. These nodes perform all data-related operations (indexing, searching, aggregating) on local shards. These are the worker nodes of a cluster and need more disk space than any other node type.
- Coordinating nodes – Delegate client requests to shards on the data nodes, collect and aggregate the results into one final result, and send this result back to the client. Coordinating nodes manage outside requests like the OpenSearch Dashboard and other client libraries.
OpenSearch clusters create a sound architecture that makes it easy to index or group information, which is needed for search operations. Furthermore, a shard can be created to hold documents and run search queries. The shards can be created in multiple nodes to speed up the search for information. A replica shard can even optimise the search speed when performed. This is why OpenSearch architecture makes for a powerful and flexible search engine that can serve multiple use cases.
Summary
OpenSearch has good search service, data storage, and visualisation features, making it straightforward to address multiple use cases – from application search, log analytics, data observability, data ingestion, and more. Secondly Its architecture is designed to help ensure that optimised search and analytics capabilities are implemented. And naturally, OpenSearch is gaining a lot of traction because of its open-source licence.
Be part of the ‘search’ and open source innovation
Would you like to contribute to OpenSearch and other open-source projects? Here are a few things to check out:
- Join the OpenSearch forums, community meetings, and community projects.
- The OpenSearch roadmap is rapidly developing, and you can also contribute.
- Stay informed about our Charmed Operators and innovations in the Juju community. You can join some community discussions in Mattermost and Discourse.
- The Ubuntu community covers a wide range of topics about operating systems and different open-source technologies.
Canonical solutions for OpenSearch
Ubuntu Pro + Support
Get your data solutions secured with Canonical and Ubuntu .The Ubuntu Pro license provides security patching for critical and high-severity Common Vulnerabilities and Exposures (CVEs) with ten years of security maintenance. In addition to this, we offer direct 24/7 access to a world-class, enterprise open source support team through our web portal, knowledge base or by phone.
Consulting Services
Our team of experts is here to help you get started with your database, providing guidance for new data-related projects design and assistance migrating your application.
OpenSearch Operator
OpenSearch is a fantastic open source search and analytics suite. However, operating and supporting a production OpenSearch solution can be complex and challenging.
Canonical and the community are developing an open source operator called Charmed OpenSearch, making it easier to operate OpenSearch on physical, Virtual Machines (VM) and other wide range of cloud and cloud-like environments in an automated way.The Charmed OpenSearch operator is available for the open source community to use. Learn more about the ‘edge’ version of the operator in the Charmed OpenSearch Technical documentation.
Talk to us today
Interested in running Ubuntu in your organisation?
Newsletter signup
Related posts
What is NoSQL and what are database operators?
In the previous blog, SQL vs NoSQL Database, we discussed the difference between two major database categories. In a nutshell, the main difference between...
Running MongoDB on Kubernetes
Running databases like MongoDB in public, private and hybrid environments provides multiple benefits. Kubernetes provides the additional advantages of...
SQL vs NoSQL: Choosing your database
IT leaders, engineers, and developers must consider multiple factors when using a database. There are scores of open source and proprietary databases...