
Universal Modeling Language for Service-Oriented Architectures: Part 2

Samuel Cozannet
on 7 May 2015
In the first part of this two part blog we looked at why Canonical believes a new language is needed for modeling modern applications in the cloud.
In this second blog we will apply these high-level concepts to build a modular and scalable sentiment analysis application with Juju, using components such as Kafka, ZooKeeper, Storm and Node.js. We’ll then use Juju to swap out Storm for Spark seamlessly!
Modeling in action
Context
One of the first applications I created at Canonical was a Twitter Sentiment Analysis solution. I found a great article by Kenny Ballou who built a similar application with Kafka and Storm. But Kenny didn’t stop at Storm, he also coded the very same demo for Spark streaming.
This is a perfect example for our new modeling language. Business owners generally don’t care what technologies are used for the backend of their sentiment analysis application. The use of Spark or Storm is an engineering choice. It’s a choice that Engineers may want to re-evaluate over time as both visions are valid. However from a service perspective they are similar and business owners do not and should not concern themselves with the engineering specifics.
Let’s see how we can represent this application with our universal modeling language, build it from scratch, then modify it and scale the components independently.
Service Model
Our application’s purpose is to collect tweets matching a certain hashtag(s), perform sentiment analysis on the stream, then publish the result on a dashboard.
At the highest level, the services we need are:
- Tweet Reader: connects to Twitter and grab tweets from the streaming API, then makes them available to other services;
- Tweet Processor: consumes tweets and extracts the value out of them. In our case, a positive and a negative score for each tweet;
- Visualization: consumes the tweets and their sentiment scores to display the result in a human readable format.

First Approach: Storm
Charm Model
In Juju, a micro-service is represented by a charm. Technically a charm is a set of scripts that follow a strict naming convention to describe how to install, run, scale and integrate the individual micro-service. A service is a collection of charms orchestrated together.
Let’s see how we can break down our 3 services:
Tweet Reader
Kenny’s solution is based on Apache Kafka. Kafka is a pub/sub messaging system built at LinkedIn that can work at scale and process big data pipes. It has recently been added to the major Hadoop distributions beside Apache Flume.
Kafka’s model requires 3 sub-services:
- A producer to read
- A broker to make available to other services
- A Service Management tool, called ZooKeeper

Tweet Processor
Storm Cluster
Storm needs 3 services to run as well:
- A Service Management Tool
- A Storm Server, called Nimbus, that is used to ship Storm Apps (topologies) to…
- Storm Workers, or agents, that will get simple tasks to do, run them and report to their Server
Those services are related together. Nimbus knows how to speak to its agents, the other way around, and all of them know how to speak to the Service Management System.
Code injector
We introduce a fourth service in our model: the code injector. In any Big Data application, infrastructure and applications are two distinct objects. The role of the infrastructure is to provide standard plugs to developers so they can ship code and data in, and collect intelligence (information) out. Think of the Big Data infrastructure as the Lego box and the application as the manual.
We have modeled that by creating a service which connects to raw code and ships it into the infrastructure automatically. We call this the Pluggable Architecture Model.
The code we ship is dynamic and open to developers. It can be changed and that doesn’t affect the model or the infrastructure. The only thing that it needs to know is how to speak to the visualization engine and where to find the tweets.

Visualization
We are going to need a service to expose a website on the Internet (a web server), and a cool dashboard solution to grab the results.
Kenny was familiar with Node.js but you can use any number of other technologies provided they expose the same method to collect tweets and their results.

End Result
OK, we have modeled our application through 3 high level services, which we broke down into sub-services. We made our infrastructure flexible by connecting it to the outside world in 3 places (tweets, processing code, visualization).
In the Juju GUI, this is what it looks like:

Second Approach: Spark
This version of the application fulfills the same goal: connect to Twitter, grab tweets, process them and display the result.
Furthermore since we already have a perfectly working Tweet reader and visualization layer we’d like to keep those as-is and really focus on the processing engine. Let’s see how our model can make that happen.
Charm Model
Tweet Processor
Spark Cluster
There are many ways to run a Spark Cluster. As we want to leverage our expensive Data Lake service, we’ll reuse a Hadoop Cluster, made of:
- Storage
- Compute
- Resource Management (YARN)
- Spark

Code injector
We reuse our previous idea. To make it easy for developers to integrate with our system, we create a pluggable interface that connects to code and ships it into our cluster.
This was made possible because we respected the relations between services. Spark knows how to talk to Kafka as does Storm. The intelligence of the relation is stored in the charm.
End Result
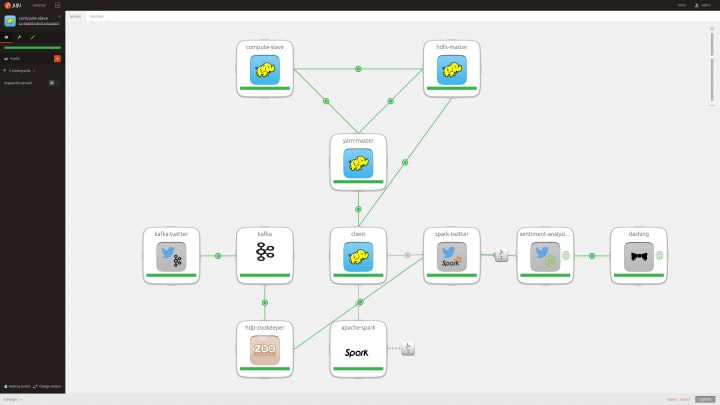
The below image shows how it looks when modeled with Juju.
Units and Scaling out
You may have noticed that I didn’t mention units in the service sections.
Units are maybe the only item in the language that speaks to a more technical audience. Units are the expression of scale. A service may run on 1000 nodes or just 2. In the Juju GUI, units are not represented.
You might also have noticed I didn’t talk about the red “Z” icon. That is how those solutions incorporate dynamic auto-scaling. Z stands for Zabbix, a monitoring service. Zabbix is smart enough to understand that the services it monitors are in good shape or under heavy load. In the latter case, it will tell Juju to scale out the service or add units. If the load is very low, it will tell Juju to scale in, until the demand is there.
What Happened?
In this post, we showed how a complex business application can be broken down into a limited set of Services, talking together through standard Relations.
We then sub-divided each service into micro-services and put together a complete architecture answering the application requirements.
Next we replaced a third of the application components with others without changing a single line of code in the rest of the infrastructure.
Finally we showed how each service can be monitored and scaled out/in independently of the others.
We did all that with Juju, a universal modeling language developed by Canonical.
Conclusion
In many projects I have been involved in and regardless of how technical or business oriented my role was, building the dictionary and vocabulary of the application was an important step and a key to the success (or failure) of the project. While it is manageable to share a language in small teams it is challenging at scale.
Juju is a form of universal modeling language. The concept of ‘Service’ speaks to the Business owner as much as to the Devs or Ops. ‘Relation’ is a common word we use to define how two objects interact. ‘Units’ encompass the notion of atomicity.
Together, and despite their apparent obviousness, they form a powerful abstraction – a universal vision of applications.
We see Juju adoption rising quickly as the language spreads. As a consequence the charm ecosystem grows offering an exponential number of options to end users. For application developers and System Integrators adopting Juju it’s like creating their first iPhone application. We’re being revolutionizing the creation and consumption of applications.
References
- Initial blog post about Apache Storm
- Initial blog post about Apache Spark
- Code repositories
Talk to us today
Interested in running Ubuntu in your organisation?
Newsletter signup
Related posts
Implement an enterprise-ready data lakehouse architecture with Spark and Kyuubi
Here at Canonical we are excited to announce that we have shipped the first release of our solution for enterprise-ready data lakehouses, built on the...
Accelerating data science with Apache Spark and GPUs
Apache Spark has always been very well known for distributing computation among multiple nodes using the assistance of partitions, and CPU cores have always...
Cut data center energy costs with bare metal automation
Data centers don’t have to be power-hungry monsters. With smart automation using tools like MAAS, you can reduce energy waste and operational costs, and make...