
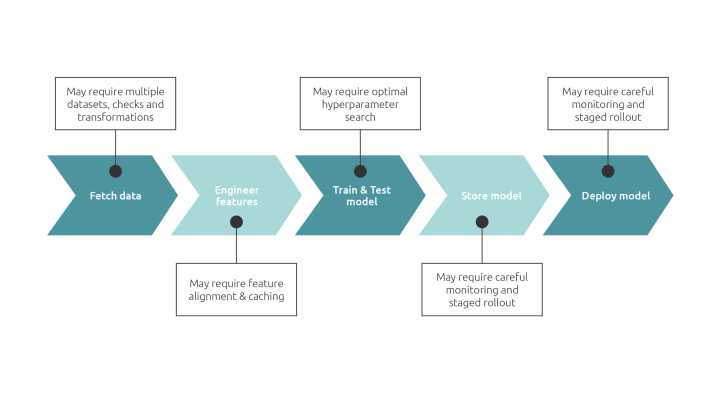
Top 5 MLOps challenges

Andreea Munteanu
on 3 March 2023
After ChatGPT took off, the AI/ML market suddenly became attractive to everyone. But is it that easy to kickstart a project? More importantly, what do you need to scale an AI initiative? MLOps or machine learning operations is the answer when it comes to automating machine learning workflows.
Adopting MLOps is like adopting DevOps, you need to embrace a different mindset and way of working. However, the return on investment that this kind of initiative generates is worth the effort. When looking at the big picture, there are two key aspects to consider. On one hand, MLOps is a practice that is relatively new, so it is completely normal to face challenges along the way. On the other hand, MLOps is evolving very fast, so solutions are appearing every day. What do companies typically struggle with and how can they overcome the most common MLOps challenges? We’ll dig into these questions in this blog.

MLOps Challenge #1: Lack of talent
Glassdoor counts 30k+ jobs related to data science and 15k+ jobs related to ML engineers that require a different level of experience, studies and skills. A career in data science has become very attractive and there are many opportunities in the market.
Analysing this data from a different angle, enterprises are investing more and more in the workforce to support machine learning initiatives. They are prioritising AI projects and investing not only in equipment but also in talent. However, this creates challenges related to finding skilled people and then reducing attrition in teams that are specialised in ML and data science. Lack of skills and employee churn influence the delivery of the ML lifecycle, as well as the timelines needed to kick off any new initiatives.
Mitigating this challenge is difficult, due to its competitive nature. Hiring remotely is one option, as it increases the chances to get access to more skilled people. Another great opportunity is to consider young talent, who can develop skills within the company, through internships or graduate programs. Whereas this is a long-term strategy, for short-term solutions, hiring companies who offer consultancy services can help enterprises get started with their AI journey. Depending on their AI readiness, companies can seek guidance for use cases, MLOps architecture or even proofs of concepts.
MLOps Challenge #2: Getting started
Getting AI projects off the ground is a challenge for most enterprises.
Starting with AI is as simple as having a business case. Answering these three main questions is going to help get a better idea of what you actually what to achieve:
- What problem are you trying to solve?
- Do you have realistic expectations?
- Do you have the right data?
In short, to get an AI initiative off the ground, you need to start with the end in mind and build towards that. Then, you can assess your company’s AI readiness and create your own program. Questions that consider the gap, the key factors, common pitfalls to avoid and infrastructure challenges help companies look more in-depth at how ready they are to get started with AI. Answering these questions leads to the design of the entire AI initiative. Ultimately, this design should help your team prioritise, define a budget and set proper timelines.
MLOps Challenge #3: Data
Data is at the heart of any AI project. It is a critical part that can either make or break any initiative. Validity checks are required in order to assess both data quality, and data access points. Although it seems prevalent everywhere now, data has not always been a priority for most companies. This is why data collection processes are often not very well defined, resulting in data that is unclean and inconsistent.
Data preparation overall is not easy. Organisations can face great challenges when it comes to data governance, gathering and storing. Often, data comes from multiple sources, which leads to mismatches in values and formats. From another point of view, machine learning models rely on large amounts of data, which is often difficult to deal with.
Addressing this challenge has multiple nuances because it has implications at different levels. Treating data with diligence is probably the secret to being successful. Limiting data discrepancies and having centralised data storage ease the preparation phase of the data. Data versioning solves problems that arise from changes that appear in the data.
MLOps Challenge #4: Security
Machine learning often operates with very sensitive data and on sensitive projects. Thus, ensuring the environment is safe is essential for the long-term success of the project. A recent AI adoption report from IBM states that 1 in 5 companies cite difficulties in ensuring data security. As a result, a growing number of people are addressing this problem, which explains why 25% of the respondents are security professionals.
Amongst the challenges that are lying around security, running outdated libraries is the most common one. Often users are not aware that they have multiple vulnerabilities that represent an opportunity for malicious attacks.
Another security pitfall is related to the model endpoints and data pipelines which are not properly secured. These are sometimes publicly accessible, potentially exposing sensitive metadata to third parties. Endpoints are a development environment and treating them like that means having clear security standards that ensure not only the security of the project, but also data security.
Security can be a challenge for any MLOps environment, so running software that offers security patching and support is essential for the existence of the project and its deployment to production. Using tooling that has a multi-tenancy option secures the internal environment, the privacy of the data and the safety of different initiatives that can be sensitive to the public.
MLOps Challenge #5: Scaling up
As McKinsey mentions in The state of AI in 2022, many organisations have largely shifted from experimenting with AI to actively embedding it in enterprise applications. It confirms on one hand the commitment that companies have towards AI projects, but on the other hand, it raises a lot of questions regarding the knowledge and ability to scale up. From having the right workflow and tools to deploy and monitor models to productions, all the way to the infrastructure needed to support such an initiative, companies will have to quickly adapt and learn new practices.
Open source is preferred by many for machine learning. End-to-end MLOps platforms such as Charmed Kubeflow are one of the open-source options available on the market. With a suite of tools that data scientists are already used to, it addresses multiple needs related to scaling such as automation, monitoring, alerting, integration, and deployment. Ideal to address the most common MLOPs challenges.
Learn more about MLOps
- [Webinar] Intro to MLOps
- [Webinar] Hyperparameter tuning with MLOps platform
- [Whitepaper] A guide to MLOps
- [Blog] From model-centric to data-centric MLOps
- [Blog] What is MLOps going to look like in 2023
Enterprise AI, simplified
AI doesn’t have to be difficult. Accelerate innovation with an end-to-end stack that delivers all the open source tooling you need for the entire AI/ML lifecycle.
Newsletter signup
Related posts
Let’s meet at AI4 and talk about AI infrastructure with open source
Date: 11 – 13 August 2025 Booth: 353 Book a meeting You know the old saying: what happens in Vegas… transforms your AI journey with trusted open source. On...
Beyond tokens per watt – using Ubuntu 26.04 LTS for AI
Tokens per watt (TpW) – the measure of useful AI work produced per watt of energy consumed – is the metric at top of mind for CEOs, heads of AI, and...
Securing AI agent workflows on Ubuntu with the new NVIDIA OpenShell snap
By packaging OpenShell as a snap, Canonical is enabling enterprises to confidently run next-generation agentic workflows across local devices, hybrid...