
What is MLOps?

Andreea Munteanu
on 14 December 2022
Tags: AI/ML , Kubeflow , machine learning , MLOps
MLOps is the short term for machine learning operations and it represents a set of practices that aim to simplify workflow processes and automate machine learning and deep learning deployments. It accomplishes the deployment and maintenance of models reliably and efficiently for production, at a large scale.
MLOps is slowly evolving into an independent approach to the machine learning lifecycle that includes all steps – from data gathering to governance and monitoring. It will become a standard as artificial intelligence is moving towards becoming part of everyday business, rather than just an innovative activity.
What is MLOps?
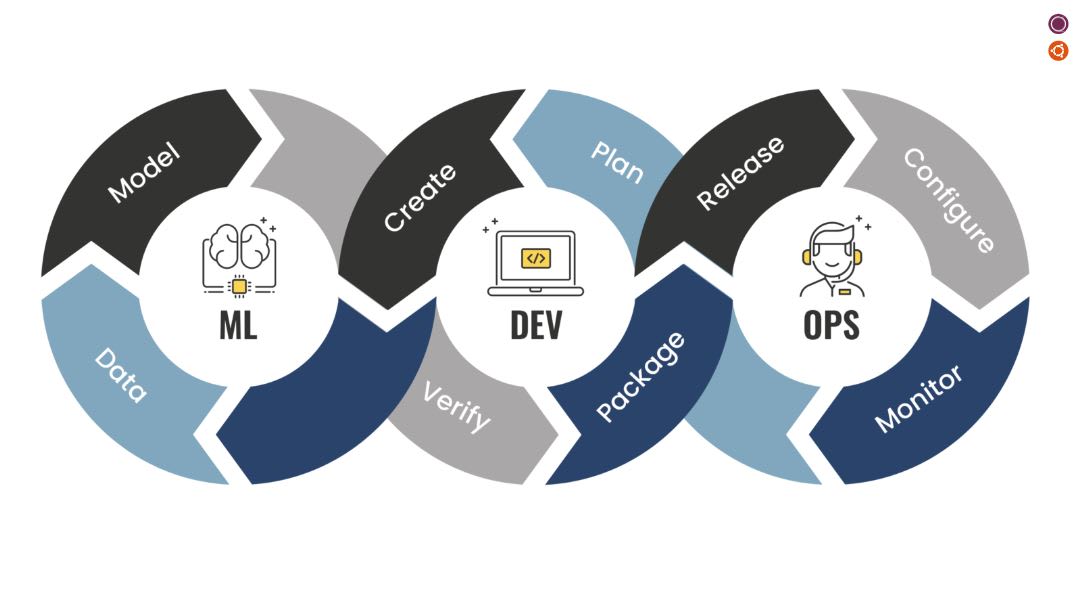
MLOps includes processes and underpinning technologies aside from best practices. It provides a scalable, centralised and governed means to improve machine learning activities.

DevOps vs MLOps
MLOPs borrows some of the widely adopted DevOps principles in software engineering, using them to take machine learning models to production faster. Much like DevOps, MLOPs offers software development strategies that focus on collaboration between various parties that are involved in the process, such as developers, system administrators, and data scientists. Whereas DevOps focuses mainly on applications and development, MLOps focuses on machine learning operations.
It includes specific activities, such as model development or data gathering. It then goes further to development, where packaging, model creation and verification play an important role. The expected outcomes of MLOPs are improvements in the code quality, faster patching, upgrades and updates, better customer satisfaction and finally, more efficient releases. Let’s explore some of the principles behind MLOps.
MLOps Principles
Machine learning development pipelines can see changes at three levels: data, machine learning model and code. When it comes to MLOps principles, they are designed to impact the ML-based software on one of these three levels.
The MLOps principles focus on:
- Versioning: It treats ML scripts, models and datasets as essential parts of DevOps processes. It tracks data and model versioning, using system controls and alerting changes.
- Testing: It needs to be performed at all levels of machine learning systems, having a different scope when ensuring performance and expected outcomes.
- Automation: The level of automation determines the level of maturity of the ML initiative. The objective of any MLOps team is to automate the deployment of ML models.
- Reproducibility: Having reproducible and identical results in a machine learning workflow, given the same input, is a key MLOps principle.
- Deployment: Model deployment should be done based on experiment tracking, which includes feature stores, containerisation of the ML stack and the ability to run on-prem, on the cloud or at the edge.
- Monitoring: Ensuring that ML models perform as expected, once deployed, is essential. Monitoring covers changes around dependencies, data, source systems and upgrades.
Why does MLOps matter?
MLOps or machine learning operations is, in fact, a set of practices that aim to simplify workflow processes and automate machine learning and deep learning deployments. It accomplishes the deployment and maintenance of models reliably and efficiently for production, at a large scale. MLOPs plays a crucial role in aligning business demands and regulatory requirements. Its benefits include:
Increased productivity
MLOps increases productivity within the machine learning lifecycle by automating processes and standardising workflows. It reduces repetitive tasks, such as data collection or data monitoring, by automating them.
Reproducibility
Automation of machine learning workflows leads to reproducibility, which impacts ML models and the ways they are trained, evaluated and deployed. Because of these benefits, both data versioning and model versioning are possible, ensuring in fact, the creation of snapshots of data as well as a feature store. This enables further model optimisation using techniques such as hyperparameter tuning or in-depth experimentation of various model types.
Cost reduction
MLOps can significantly reduce costs, especially when considering scaling up AI initiatives and serving models to production. It impacts the entire machine learning lifecycle because of the minimisation of the manual efforts that come from task automation. It also enables easier error detection and improved model management.
Monitorability
Monitoring the behaviour of a machine learning model impacts not only the artificial intelligence project but also the area of business for which it has been designed. MLOps enables enterprises to monitor the model and gain insights about model performance in a systematic manner. It allows continuous model retraining, ensuring that it constantly offers the most accurate input. Furthermore, it can send alerts in case of data drift or model drift, which also flags any vulnerability within enterprise processes.
MLOps in the machine learning lifecycle
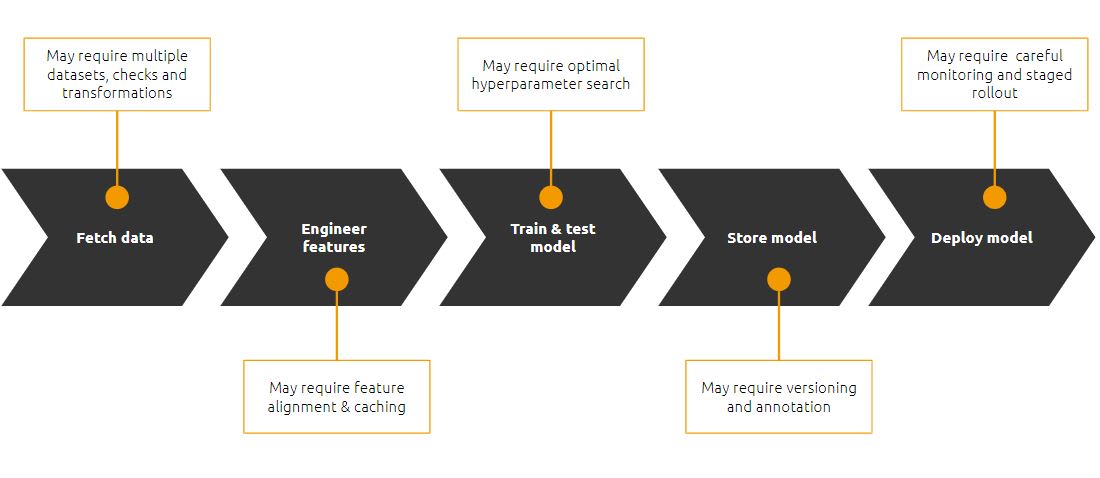
The machine learning lifecycle impacts the operations required to sustain it. Data is the heart of any AI project, so without a big enough dataset, there is no machine learning modelling taking place. Fetching data includes, on the one hand, various data sources that need to be further processed. It may also include data coming from various devices, meaning you could end up with data that is numeric, text, video and much more.
Once data is in place, you need to start processing and transforming it, such that it can be used for machine learning modelling. This includes activities that clean duplicates, aggregate and refine features and finally make features visible across data teams.
After you gather, clean up and refine your data, you need to use it to train your model. This process relies mostly on machine learning libraries, such as PyTorch or Tensorflow. You can also use more advanced techniques to optimise machine learning models. This is a phase of experimentation that leads to the creation of multiple models which are then stored. Often, it leads to model versioning as well as data versioning. Tracking model lineage, managing model artefacts and transitioning them through their lifecycle is part of the process that any AI initiative needs to take into account.
Once the review and analysis of the machine learning models is performed, deploying them is the next step. The deployment process addresses various aspects, such as model refresh frequency or alert creation, and management in case of failure.
The machine learning lifecycle relies on this complex and repetitive process but performing all of its associated activities in one tool is one of the biggest challenges that machine learning engineers face. End-to-end MLOps tools, such as Charmed Kubeflow, solve this problem, allowing specialists to handle most of the steps in one platform.
Learn about Charmed Kubeflow – an open-source MLOps platform
Charmed Kubeflow is a production-grade, end-to-end MLOps platform that translates steps in the data science workflow into Kubernetes jobs. It is one of the official distributions of the Kubeflow upstream project. Using it, data scientists and machine learning engineers benefit from having ML deployments that are simple, portable and scalable. It has capabilities that cover a wide range of tasks, from experimentation using Notebooks, to training using Kubeflow Pipelines or tuning, using Katib.
Charmed Kubeflow is a great companion for teams adopting the MLOps approach. MLOps brings together best practices to productise machine learning initiatives. With clear principles that take into account the data that is being used, the ML model and the code. As the market evolves, the need to have stable and secure tools to handle MLOpsbecomes more evident. Charmed Kubeflow addresses this challenge and allows data scientists to focus on modelling.
Learn more about MLOps
- [Webinar] Retail at the edge with MLOps: market basket analysis
- [Webinar] Hyperparameter tuning with MLOps platform
- [Whitepaper] A guide to MLOps
- [Blog] A guide to model serving
- [Blog] Kubeflow pipelines: part 1 & part 2
- What is Kubeflow?
- Quickstart guide to install Charmed Kubeflow
Get in touch with us to learn more about our MLOps offering.
Enterprise AI, simplified
AI doesn’t have to be difficult. Accelerate innovation with an end-to-end stack that delivers all the open source tooling you need for the entire AI/ML lifecycle.
Newsletter signup
Related posts
Let’s meet at AI4 and talk about AI infrastructure with open source
Date: 11 – 13 August 2025 Booth: 353 Book a meeting You know the old saying: what happens in Vegas… transforms your AI journey with trusted open source. On...
Accelerating AI with open source machine learning infrastructure
The landscape of artificial intelligence is rapidly evolving, demanding robust and scalable infrastructure. To meet these challenges, we’ve developed a...
Canonical welcomes NVIDIA’s donation of the GPU DRA driver to CNCF
At KubeCon Europe in Amsterdam, NVIDIA announced that it will donate the GPU Dynamic Resource Allocation (DRA) Driver to the Cloud Native Computing Foundation...