
%27%20fill%3D%27%23E95420%27%3E%3Cpath%20d%3D%27m15.839%205.293-1.447-2.8a.136.136%200%200%200-.051-.055.144.144%200%200%200-.074-.02h-5.8a.143.143%200%200%200-.091.03.13.13%200%200%200-.034.17.138.138%200%200%200%20.072.06l7.251%202.8a.144.144%200%200%200%20.17-.054.13.13%200%200%200%20.007-.13l-.003-.001ZM11.839%204.945.073.223A.073.073%200%200%200%20.026.221a.07.07%200%200%200-.038.027.065.065%200%200%200%20.007.086l7.962%208.182a.069.069%200%200%200%20.049.022.072.072%200%200%200%20.047-.019l3.805-3.461a.066.066%200%200%200%20.02-.061.065.065%200%200%200-.014-.03.07.07%200%200%200-.028-.02l.003-.002ZM5.382%207.183a.071.071%200%200%200-.062-.022.07.07%200%200%200-.03.011.067.067%200%200%200-.023.025l-4.13%207.696a.065.065%200%200%200-.005.046.068.068%200%200%200%20.027.038.072.072%200%200%200%20.09-.006L7.13%209.18a.066.066%200%200%200%200-.087l-1.75-1.91Z%27%2F%3E%3C%2Fg%3E%3Cdefs%3E%3CclipPath%20id%3D%27a%27%3E%3Cpath%20fill%3D%27%23fff%27%20d%3D%27M0%200h15.83v15.21H0z%27%2F%3E%3C%2FclipPath%3E%3C%2Fdefs%3E%3C%2Fsvg%3E)

%27%20fill%3D%27%23E95420%27%3E%3Cpath%20d%3D%27M1.936%202.592c.668%200%201.21-.515%201.21-1.151S2.604.29%201.936.29C1.267.29.726.805.726%201.44c0%20.637.541%201.152%201.21%201.152ZM14.56.576H3.404a1.587%201.587%200%200%201%20.024%201.69l-.026.04h11.156a.56.56%200%200%200%20.386-.15.518.518%200%200%200%20.16-.369v-.692a.502.502%200%200%200-.16-.369.543.543%200%200%200-.386-.15ZM1.936%206.701c.668%200%201.21-.515%201.21-1.15%200-.637-.542-1.152-1.21-1.152-.669%200-1.21.515-1.21%201.151s.541%201.151%201.21%201.151ZM14.56%204.685H3.404a1.612%201.612%200%200%201%20.242%201.083c-.03.215-.105.421-.219.608l-.026.04h11.157a.56.56%200%200%200%20.386-.15.518.518%200%200%200%20.16-.37v-.692a.5.5%200%200%200-.16-.369.542.542%200%200%200-.386-.15ZM1.936%2010.81c.668%200%201.21-.515%201.21-1.15%200-.637-.542-1.152-1.21-1.152-.669%200-1.21.515-1.21%201.151s.541%201.151%201.21%201.151ZM14.56%208.795H3.404a1.611%201.611%200%200%201%20.243%201.082%201.581%201.581%200%200%201-.245.648h11.156a.559.559%200%200%200%20.386-.15.517.517%200%200%200%20.16-.37v-.692a.502.502%200%200%200-.16-.368.543.543%200%200%200-.386-.15ZM1.936%2014.92c.668%200%201.21-.515%201.21-1.15%200-.637-.542-1.152-1.21-1.152-.669%200-1.21.515-1.21%201.151s.541%201.151%201.21%201.151ZM14.56%2012.904H3.404a1.611%201.611%200%200%201%20.242%201.082%201.58%201.58%200%200%201-.219.608l-.026.04h11.157a.562.562%200%200%200%20.386-.15.517.517%200%200%200%20.16-.37v-.692a.5.5%200%200%200-.16-.369.543.543%200%200%200-.386-.15Z%27%2F%3E%3C%2Fg%3E%3Cdefs%3E%3CclipPath%20id%3D%27a%27%3E%3Cpath%20fill%3D%27%23fff%27%20d%3D%27M0%200h15.83v15.21H0z%27%2F%3E%3C%2FclipPath%3E%3C%2Fdefs%3E%3C%2Fsvg%3E)
%27%20fill%3D%27%23E95420%27%3E%3Cpath%20d%3D%27M9.618.272c-.634%200-1.243.243-1.691.674-.448.43-.7%201.015-.701%201.624v4.221a1.9%201.9%200%200%201%201.362%200v-4.22a.955.955%200%200%201%20.291-.72%201.067%201.067%200%200%201%201.479%200%20.955.955%200%200%201%20.29.719v.962h1.363V2.57c0-.61-.253-1.194-.702-1.625A2.445%202.445%200%200%200%209.618.272ZM9.017%208.433c0%20.21-.065.417-.187.593a1.102%201.102%200%200%201-.499.393c-.203.08-.426.102-.642.06a1.125%201.125%200%200%201-.568-.292%201.055%201.055%200%200%201-.304-.547%201.028%201.028%200%200%201%20.064-.616c.084-.195.226-.362.41-.479a1.143%201.143%200%200%201%201.401.133c.103.1.185.217.24.347.057.129.085.268.085.408ZM2.773%205.855c-.634.001-1.242.244-1.69.674C.633%206.96.381%207.545.38%208.154v4.082a1.901%201.901%200%200%201%201.363%200V8.154a.955.955%200%200%201%20.29-.719%201.067%201.067%200%200%201%201.479%200%20.955.955%200%200%201%20.29.719v.962h1.363v-.962c0-.61-.253-1.194-.702-1.625a2.444%202.444%200%200%200-1.69-.674ZM2.166%2013.878c0%20.21-.065.415-.186.59-.121.174-.294.31-.496.39-.202.08-.424.102-.638.06a1.119%201.119%200%200%201-.565-.29%201.049%201.049%200%200%201-.302-.543c-.043-.206-.02-.42.063-.614.084-.194.225-.36.407-.476a1.136%201.136%200%200%201%201.394.133%201.024%201.024%200%200%201%20.323.75Z%27%2F%3E%3Cpath%20d%3D%27M14.752%204.76a1.789%201.789%200%200%201-.681-.126v2.411a.972.972%200%200%201-.312.682c-.193.179-.45.28-.718.28-.268%200-.526-.101-.718-.28a.972.972%200%200%201-.312-.682V4.32h-1.363v2.726c0%20.61.252%201.195.7%201.626a2.443%202.443%200%200%200%201.692.673c.635%200%201.244-.242%201.692-.673.449-.431.7-1.016.7-1.626v-2.41a1.9%201.9%200%200%201-.68.125ZM15.858%202.822c.037.225%200%20.455-.107.658a1.1%201.1%200%200%201-.49.472%201.161%201.161%200%200%201-1.302-.198%201.04%201.04%200%200%201-.206-1.251%201.1%201.1%200%200%201%20.492-.47%201.161%201.161%200%200%201%201.299.199c.166.16.276.366.314.59ZM7.907%2010.2c-.233%200-.465-.042-.681-.126V12.6a.97.97%200%200%201-.302.7%201.05%201.05%200%200%201-.728.29%201.05%201.05%200%200%201-.728-.29.97.97%200%200%201-.302-.7V9.845H3.804V12.6c0%20.61.252%201.194.7%201.625a2.443%202.443%200%200%200%201.692.674c.634%200%201.243-.243%201.692-.674.448-.43.7-1.015.7-1.625v-2.526a1.887%201.887%200%200%201-.68.127Z%27%2F%3E%3C%2Fg%3E%3Cdefs%3E%3CclipPath%20id%3D%27a%27%3E%3Cpath%20fill%3D%27%23fff%27%20d%3D%27M0%200h15.83v15.21H0z%27%2F%3E%3C%2FclipPath%3E%3C%2Fdefs%3E%3C%2Fsvg%3E)

What’s new in Charmed Ceph with Ceph Quincy on Ubuntu 22.04 LTS?

Philip Williams
on 29 June 2022
Along with the usual bug fixing, maintenance, and upstream version enablement work that goes into every Charmed Ceph release, we also worked on a number of new features in this cycle.
Stand-alone NFS shares
In Ceph, you can use CephFS for your network file share needs, but sometimes there are applications or use cases that require NFS. In Charmed Ceph we now have the option to deploy the ganesha plugin to provide NFS shares from a Ceph cluster, and whilst this was available before for Openstack with Manila, it is now fully stand-alone and has no dependencies on Openstack, perfect if you are deploying Ceph as a stand-alone storage system.
To meet our scalability goals we decided to allow the charms to be deployed in two different ways. For simplicity, multiple shares can be presented from one pair of ganesha units. For better scaling and workload isolation, a single share can be mapped to a single pair of ganesha units, and for subsequent shares, additional ganesha units will be deployed.
It was designed in this way so that users would not become bottlenecked by the performance of a pair of ganesha units handling all NFS traffic, nor experience noisy-neighbour effects between heavy NFS users.
We maintain high-availability of the NFS end-point by deploying pairs of ganesha units with corosync/pacemaker handling failover between them.
Note: the ceph-nfs charm is still in tech-preview.
Drive replacement improvements
Previously, replacing a disk was quite an involved process, requiring the tracking down of OSD IDs, UUIDs for the underlying disk, and if using bache, IDs for the caching device too.
In this release, we have streamlined the process to be straightforward and repeatable. The most important thing that this improvement brings is a higher level of safety, by reducing the risk of mixing up device IDs, and inadvertently affecting another fully functional OSD.
PMEM Investigations
In this cycle we also did some investigative work into PMEM and the potential benefits it may bring as a host side cache, using the RBD persistent write-back cache feature.
Persistent memory (or NVDIMM) is a class of storage device that resides in one or more DIMM slots of a server, but unlike normal RAM, any data written to an NVDIMM persists through server reboots. Given their location on the server mainboard they have very low latency and very high IO capabilities. Perfect for caching the most frequently accessed data!
It’s important to note that this is a relatively new feature, and one needs to be very selective about the scenarios in which it can be used. For example, if the server fails and becomes unrecoverable then the data in the cache is lost. The cache is structured so that the image/volume on the ceph cluster can be considered crash-consistent, but if the cache contains data yet to be flushed to ceph, then there is a guaranteed data loss.
Where we see this feature being useful is for highly parallelised batch processing work loads, where the loss of one part of the job isn’t catastrophic and can just be re-run.
For testing purposes we built a Ceph cluster that was highly IO constrained. Just a single node with three spinning disk OSDs in LXD containers. We then created an RBD volume of 100GB and allocated 5GB of local PMEM to that volume.
In the first test, using fio configured for 50/50 read/write without the cache in place, we were only able to achieve just over 1000IOPs. In the second with the cache in use, we were able to achieve over 27000 IOPs, obviously a huge improvement as all the IO was completed locally.
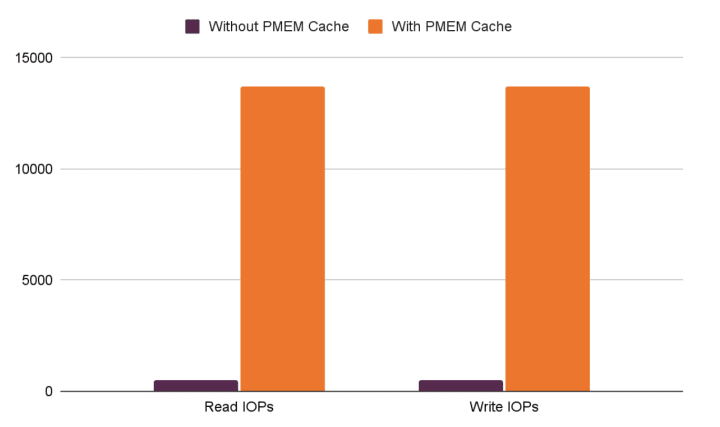
An important observation, however, is that once the fio test had completed, the process didn’t exit for quite some time, as the outstanding IOs in the local cache still had to be flushed to the Ceph cluster.
Upstream Quincy
The upstream Quincy release really feels like Ceph has reached a maturity point where the community is not just chasing new features to have parity with other storage solutions, but adding a level of polish to the feature set that has existed for quite some time.
Here are some of the features that stand out in the release notes.
RGW rate limiting
Rate limiting is really quite interesting for organisations with a large number of users – especially when there are heavy users or buckets that are accessed frequently. Applying rate limits to either of those entities (users or buckets) will help share cluster resources more fairly, and avoid noisy neighbour effects where one user or workload monopolises cluster resources. Read and/or write operations and/or bytes per minute can be used when setting these limits.
Farewell Filestore
Hopefully there are no Ceph users still deploying OSDs based on filestore, given the improvements that BlueStore brought us in terms of performance, reliability and scalability. But either way, from now on they are fully deprecated in Quincy.
LevelDB Support
Ceph Quincy no longer supports LevelDB – so it is important to remember to migrate MONs and OSDs to RocksDB prior to any upgrade to Quincy. For OSDs this will mean destroying and redeploying OSDs, and likewise for the MONs, you will need to deploy new MONs and add them to the cluster one by one, whilst removing the old MONs as quorum is reached. Just be careful that no external applications have hard-coded IP addresses to the existing MONs. Those applications won’t lose access to the cluster right away, but you may run into issues after a host reboot.
Learn more

What is Ceph?
Ceph is a software-defined storage (SDS) solution designed to address the object, block, and file storage needs of both small and large data centres.
It’s an optimised and easy-to-integrate solution for companies adopting open source as the new norm for high-growth block storage, object stores and data lakes.
How to optimise your cloud storage costs
Cloud storage is amazing, it’s on demand, click click ready to go, but is it the most cost effective approach for large, predictable data sets?
In our white paper learn how to understand the true costs of storing data in a public cloud, and how open source Ceph can provide a cost effective alternative!
Interested in running Ubuntu in your organisation? Talk to us today
A guide to software-defined storage for enterprises
Ceph is a software-defined storage (SDS) solution designed to address the object, block, and file storage needs of both small and large data centres.
In our whitepaper explore how Ceph can replace proprietary storage systems in the enterprise.
Interested in running Ubuntu in your organisation? Talk to us today
Performant, reliable and cost-effective cloud scaling with Ceph
Canonical Ceph simplifies the entire management lifecycle of deployment, configuration, and operation of a Ceph cluster, no matter its size or complexity. Install, monitor, and scale cloud storage with extensive interoperability.