
What is a vector database?

Giulia Lanzafame
on 3 October 2024
Tags: OpenSearch , search engine , vectordatabase

A vector database is a data storage system that organises information in the form of vectors, which are mathematical representations. These databases are designed to store, index, and query vector embeddings or numerical representations of unstructured data, including text documents, multimedia content, audio, geospatial coordinates, tables, and graphs. This setup enables fast retrieval and similarity searches, making it especially useful for efficiently managing and finding complex, high-dimensional data that is difficult to query using traditional methods.
Artificial intelligence and machine learning continue to become more widely adopted, making vector databases increasingly vital as the AI industry reaches new heights of interest and innovation. Large language models and generative AI have fueled the rise of vector databases by efficiently handling the complexity of unstructured data, such as text, images, and videos. This is because, unlike traditional relational databases, which organise structured data into rows and columns, these systems excel at managing this type of unconventional data.
In fact, to address this challenge, vector databases convert unstructured data into vector embeddings—numerical representations that preserve the data’s relational context and semantic properties. Beyond revolutionising data management and storage, vector databases play a crucial role in enhancing the understanding and contextualisation of information, a core capability of artificial intelligence models.
The recent surge in investment in this area highlights the critical role vector databases play in modern applications. They offer high speed and performance through advanced indexing techniques while supporting horizontal scalability and handling large volumes of unstructured data. They are a cost-effective solution compared to training genAI models from scratch, reducing costs and inference time. This is because a vector database can recognise similarities between data points (for example a pen and a pencil) and as such they will enable rapid prototyping of GenAI application boosting accuracy and reducing hallucinations through prompt augmentation. These are all tasks which can be mostly automated through a vector database and which would require a number of lengthy steps otherwise.
Furthermore, they are flexible, suitable for various types of multidimensional data and different use cases, such as semantic search and conversational AI applications and are particularly valuable for real-time applications like personalised content recommendations on social networks or e-commerce platforms. Finally, they improve the output of AI models, such as LLMs, and simplify the management of new data over time.
How do they work?
The idea behind the operation of vector databases is that while a conventional database is optimised for storing and querying tabular data consisting of strings, numbers and other scalar data, vector databases are optimised for operating on vector-type data. Therefore, query execution on a vector database differs from query execution on a conventional database. Instead of searching for exact matches between identical vectors, a vector database uses similarity search to locate vectors that reside in the vicinity of the given query vector within the multidimensional space.
Hence in traditional databases, we usually search for rows in the database where the value of a given field exactly matches the filters in our query. In contrast, in vector databases, on the other hand, we apply a similarity metric to find a vector that is as similar as possible to our query. This approach aligns more closely with the intrinsic nature of data and offers a speed and efficiency that traditional research cannot match.
To perform a similarity search, vector databases use advanced indexing techniques, such as approximate neighbour search (ANN), hierarchical small navigable world (HNSW), Product Quantization (PQ) and Locality-sensitive hashing (LSH), in order to optimise performance and ensure low latency during search operations. Vector indexing is crucial to manage and retrieve high-dimensional vectors efficiently.
An example of ANN query is the ‘k nearest neighbours’ (k-NN) query. In this case, vectors represent points in N-dimensional spaces, effectively describing the selected data set through mathematical objects. Using low-latency queries, through a k-NN search, we will be able to cluster the data set into k different groups, meaning that we achieve the maximum possible similarity in neighbouring data points.
Here’s a common pipeline for a vector database:

Figure 1: Pipeline of a vector database
- Indexing: After transforming the raw data into embeddings, the vector database organises vectors using algorithms such as ANN. This process maps the vectors to a data structure designed to facilitate functions such as search and retrieval.
- Querying: The vector database compares the query vector against the vectors in the dataset, using a similarity search with a predefined user-defined metric. This will allow us to find the nearest neighbours to the query vector, maximising the similarities.
- Post-Processing: In some instances, the vector database retrieves the nearest neighbours from the dataset and applies post-processing to generate the final results. This step may involve relabelling the nearest neighbours with an alternative similarity measure.
The diagram below shows a more in-depth view of the function of the indexing and querying phases:

Figure 2: Storing path diagram for vector databases
In particular, the indexing phase begins with selecting a machine learning model suitable for generating vector embeddings based on the type of data we are working with, such as text, images, audio, or tabular data. Once the appropriate model is chosen, data will be converted into embeddings, or vectors, by processing it through the embedding model. Along with these vector representations, relevant metadata will be saved as it can be used later to filter search results during similarity searches. The vector database will then index the vector embeddings and metadata separately, using various indexing methods like ANN. Finally, the vector data will be stored alongside these indexes and the associated metadata, enabling efficient retrieval and querying.

Figure 3: Query path diagrams for vector databases
The querying phase, which consists of running queries in a vector database, is usually made up of two parts: the first is the input of the data that needs to be matched, like a picture which is compared to others (input), and the second one is a metadata filter to exclude results with certain known traits, like leaving out images of dresses in a specific colour. This filter can be applied either before or after a similarity search. The data is processed using the same model that was used to store it in the database, and then the search retrieves similar results based on how closely they match the original data.
LLM use case: Using OpenSearch vector capabilities
Charmed OpenSearch, an open source OpenSearch operator, provides vector database functionality through an enabled k-NN plugin, enhancing conversational applications with essential features like fault tolerance, access controls, and a powerful query engine. This makes Charmed OpenSearch an ideal tool for applications like Retrieval Augmented Generation (RAG), which ensures that conversational applications generate accurate results with contextual relevance and domain-specific knowledge, even in areas where the relevant facts were not originally part of the training dataset.
A practical example of using Charmed OpenSearch in the RAG process involves using it as a retrieval tool in an experiment using a Jupyter notebook on top of Charmed Kubeflow to infer an LLM.
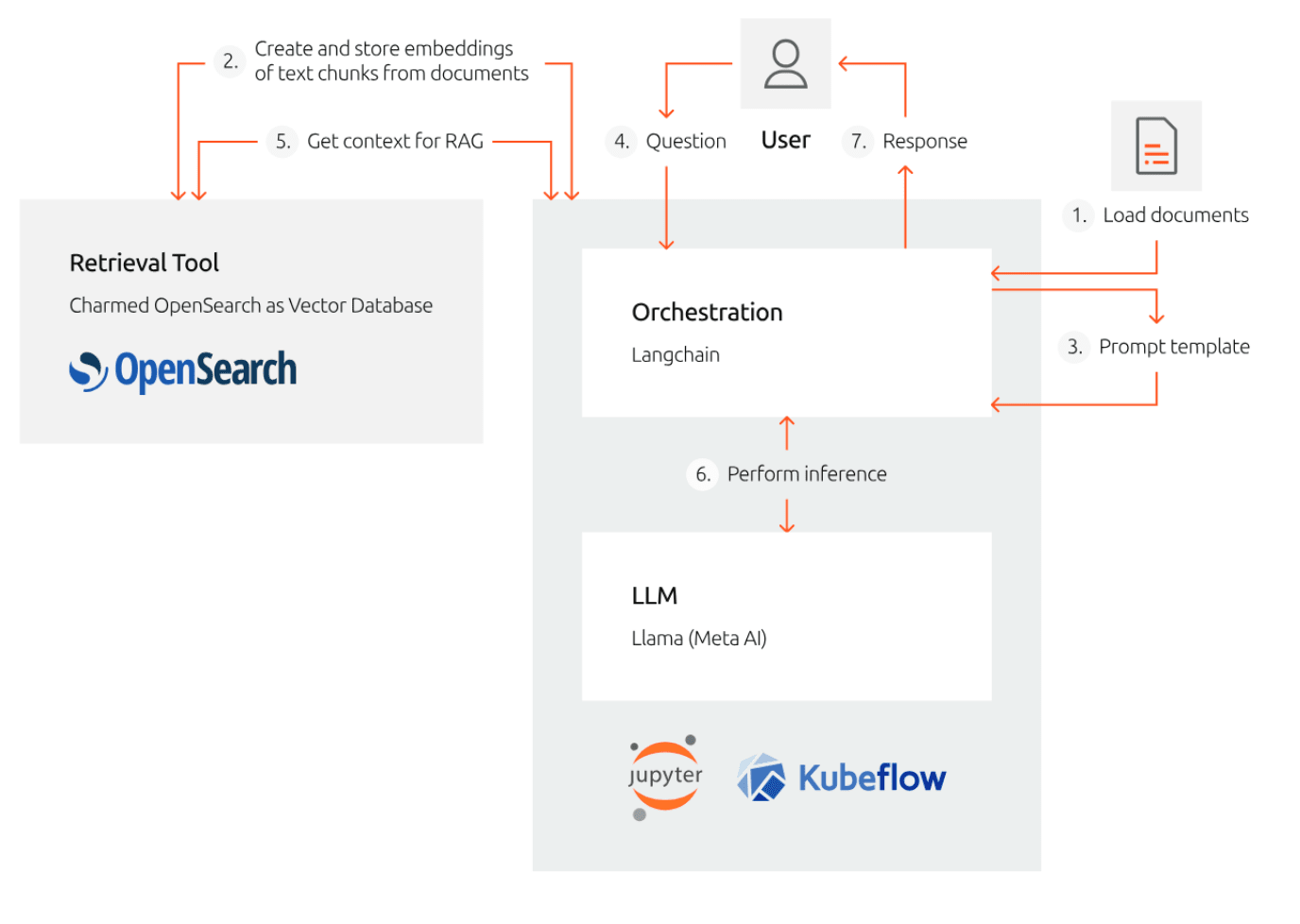
Figure 5: RAG workflow with open source tooling
LLMs Retrieval Augmented Generation (RAG) using Charmed OpenSearch
Summary
Vector databases have become increasingly important as AI applications in fields like natural language processing, computer vision, and automated speech recognition. Unlike traditional scalar-based databases, vector databases are specifically designed to handle the unique challenges associated with managing these embeddings in production environments, offering distinct advantages over both conventional databases and standalone vector indexes.
To provide you with a deeper understanding of how vector databases work, we’ve explored the core elements of a vector database, including its operational mechanics, the algorithms it employs, and the additional features that make it robust enough for production use.
Canonical for your vector database needs
- Starting a new project that requires a vector database? Contact us
- Watch the webinar or Download the whitepaper: Vector databases for generative AI applications.
- Download the whitepaper about accelerating vector search performance of Charmed OpenSearch: the benefits of Intel® AVX-512.

What is OpenSearch?
OpenSearch is an open source search and analytics suite that developers use to build solutions for search, data observability, data ingestion and other use cases
If you’re curious about the OpenSearch project and how it works, you’ve come to the right place.
Newsletter signup
Related posts
OpenSearchCon 2023 is coming, meet us in Seattle
The search, analytics, and database communities are buzzing with excitement as the countdown to OpenSearchCon 2023 begins. This second annual conference will...
Meet Canonical and OpenSearch.org at Open Source Summit Europe 2023
We are excited to celebrate all things open source at the upcoming Open Source Summit Europe 2023 in the beautiful city of Bilbao, Spain. The event will take...
Building an end-to-end Retrieval- Augmented Generation (RAG) workflow
In this guide, we will take you through setting up a RAG pipeline. We will utilize open source tools such as Charmed OpenSearch for efficient search retrieval...