
Mojo: Juju Service Orchestration distilled

Tom Haddon
on 13 January 2015
Tags: Juju
In Canonical’s IS Department we use Juju for service orchestration. It’s a great tool for quickly spinning up complex services, tying them together and scaling them out or in as needed. We use it for everything from the ubuntu.com website itself to click-packages, the system that underpins the Ubuntu phone. We even use it to deploy the OpenStack instances that these services run on. All in all we have more than 60 Juju environments in production.
We started working with Juju in production in October 2012, and over time, the way in which we’ve chosen to deploy and manage those environments has evolved significantly. We started out with shell scripts with lots of juju deploy commands, followed by juju set commands to configure services, juju add-relation commands, and whatever other steps were needed, such as exposing services, setting up nova security groups, etc..
We realised we needed a better approach that gave us more consistency and clarity, and allowed us to collaborate on service deployments with developers. We also needed something that allowed us to test changes to Juju environments before doing so in production – continuous integration (CI) for Juju. Our best practices for Juju deployments and CI were distilled into Mojo, and we’re happy to now be able to make Mojo available as an Open Source project on Launchpad.
So what is Mojo and how does it fit into the Service Orchestration story for Juju?
Mojo is a system of configuration and tools for verifying the success of Juju environment deployments. It gives you a structured means of having an entirely repeatable deployment process. By “deployment process” here, we mean going from an entirely empty environment with no VMs running to VMs with the services deployed on them, relations established between each, and a fully working service.
Mojo ensures reproducibility of builds by enforcing a separation of collecting build resources from running build steps in a network-isolated environment. It minimises exposure to production secrets (SSL certificates, production passwords, etc.), but maximises exposure to all other production deployment parameters.
It also allows you to test any other operations you may want to do on a Juju environment besides just an initial service deployment, such as scaling out, updating charms, updating code or content on running service units, uploading data into your application or whatever you need.
One specification, multiple environments
By having these steps all defined within a specification, you can test them in one Juju environment, and then run them again in your production Juju environment. This also means developers and sysadmins can more easily collaborate on service changes, because the steps being taken are by definition scripted and tested.
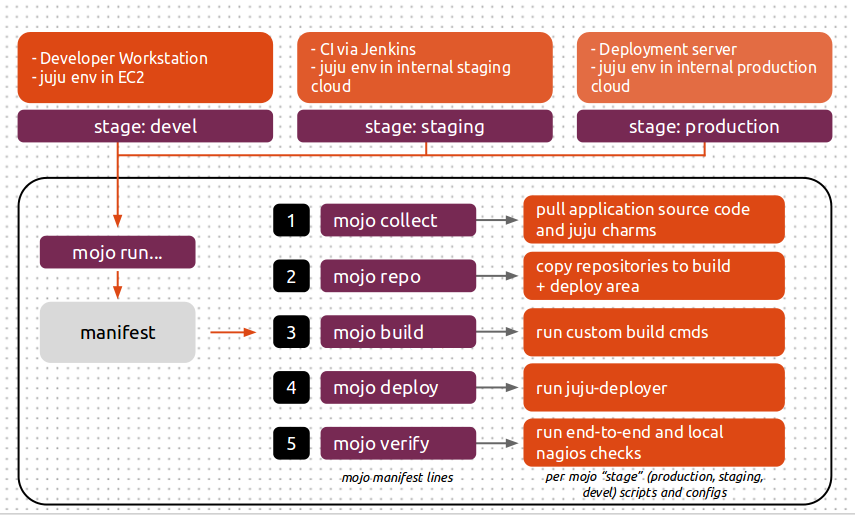
This diagram shows how you can use the same Mojo specification and manifest with different stages to deploy into three different environments for development, staging and production.
This is the first in a series of three posts about Mojo. Next time around we’ll dive a bit deeper into a Mojo specification branch to see how it fits together, and the final post will go through an example deployment. Stay tuned for those!
About the author
Tom Haddon is a squad lead within Canonical’s IS department. He manages a globally distributed team of senior systems administrators rotating between three functions: Projects, Operations and Webops (devops). He has a strong focus on cloud technologies including OpenStack, Juju and MAAS.
Talk to us today
Interested in running Ubuntu in your organisation?
Newsletter signup
Related posts
Cut data center energy costs with bare metal automation
Data centers don’t have to be power-hungry monsters. With smart automation using tools like MAAS, you can reduce energy waste and operational costs, and make...
The hitchhiker’s guide to infrastructure modernization
One of my favourite authors, Douglas Adams, once said that “we are stuck with technology when what we really want is just stuff that works.” Whilst Adams is...
Effortless observability for Django applications
Observability is critical for web operations to ensure that the application is working as expected and to identify any potential issues. However, setting up...