
AI in telecom: an overview for data scientists

Maciej Mazur
on 5 February 2021
Tags: Charmed Kubernetes , Kubeflow , ML , MLOps , Telecommunications
I have seen many junior data scientists and machine learning engineers start a new job or a consulting engagement for a telecom company coming from different industries and thinking that it’s yet another project like many others. What they usually don’t know is that “It’s a trap!”.
I spent several years forging telecom data into valuable insights, and looking back, there are a couple of things I would have loved to know at the beginning of my journey. Regardless of the part of the telecom company you are working on, be it radio network optimization, traffic monitoring and anomaly detection, or churn detection and prevention, the issue you’ll immediately get into is access to data sources.
Where to keep the data ?
You are probably used to a large data set residing in a bucket on AWS or Azure. Unfortunately, in many cases, a mobile operator does not have an option to use public cloud whether because of local regulations or security reasons. This makes it very difficult to use modern tooling like Google Big Query. In most cases, databases that you would consider “legacy” and too expensive are still crucial to connect a voice call. You may think, “Ha! I have a powerful desktop with 4 latest nVidia GPUs, so no problem”. While this might be true when working in a secure office environment, when working from home it is impossible to download customer related data to your local machine, even with anonymised PIIs.
Just use Kubernetes
Ok, so what is a viable solution? Every mobile operator is now looking into Virtual Network Functions (VNFs) as well as Containerized Network Functions (CNFs). CNFs don’t see a wide production usage yet, but you can definitely find a Kubernetes environment in the network. Since Kubernetes is planned to be used as a CNF platform, it is meant to be well connected to other important systems, properly secured etc… When you get access to this environment, you can use KubeFlow, a containerized ML Ops solution which provides a straightforward way to deploy best-of-breed open-source systems for machine learning to diverse infrastructures. Thanks to charms, you can install KubeFlow with a single command.

After the installation, you can access your familiar Jupyter notebook, nVidia toolkit acceleration, as well as all the other popular tools and frameworks. Kubeflow is also a full ML Ops platform, allowing you to build data pipelines and productize models. You may think now – “Ok, one command and I’m ready to work!”, but remember… It’s a trap! Actually, You may now have an environment to work in, but you are missing the datasets.
Self organizing networks example
The next pitfall is the data itself. In order to narrow it down, let’s focus on Self Organizing Networks or SON, one of the use cases where machine learning is used in telecommunications. In a nutshell, SON is an automation technology designed to accelerate and simplify the planning, configuration, management, optimization and healing of mobile radio access networks. When working on SON, you’ll touch three main areas: self-optimization, self-healing, and self-configuration. In all of these cases your main data would be current and historical configuration, alarms coming from network elements, radio performance metrics in forms of real time, aggregated KPIs, and a ton of metadata. For each and every data type you would have to find a single source of truth. This can be tough because most networks usually have two or more vendors with slightly different ways of configuring and monitoring their equipment. Fortunately, most networks also have an umbrella level system that collects and transforms data into a common format. If you are not working on something that needs to be optimized in real-time, this would be your go to data source.
Productizing the model with Kubeflow
Now that you developed your new model, it is time to test it. If you have chosen the Kubeflow path you can serve a model as an endpoint via any of the serving modules (KFServing).
You can also export a docker container for your devops team to run your model in a testing environment. The superpower of Charmed Kubernetes is a possibility to relate charms to each other. Let’s assume that you have some of your data in ElasticSearch and want to serve them using Kafka because that’s how yout target VNF receives instructions. If you are not proficient with devops, it might be challenging to set this up. However, with charms, you can relate components with a single command and achieve a setup like this in matter of minutes:
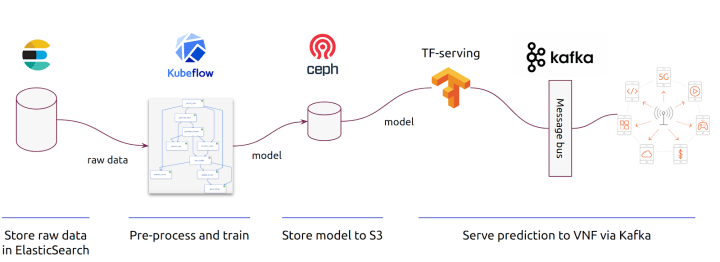
Using Kubeflow as your work environment is a great time saver and a best choice for data scientists working in telecom space. It allows you to focus on what’s important – working on your model to deliver more value or some more data cleaning depending if you see a glass half full or empty.A
If you are a data professional working in telco space I would also encourage you join OpenRAN discussions, especially in a sub group – RAN Intelligence & Automation (RIA) where you can influence the future of Machine Learning in telecommunications.
What is Kubeflow?
Kubeflow is the foundation of tools for AI Platforms on Kubernetes. AI platform teams can build on top of Kubeflow, deploy the entire reference platform, or use each project independently to meet their specific needs.
The Kubeflow reference platform is composable, modular, portable, and scalable, backed by an ecosystem of Kubernetes-native open source projects for each stage of the AI/ML Lifecycle.
Install Kubeflow
The Kubeflow project is dedicated to making machine learning workflows on Kubernetes simple, portable and scalable. With Charmed Kubeflow, you can forget about operational issues and platform compatibility. Thanks to the power and flexibility of Juju, our open source operator framework, you can deploy Charmed Kubeflow on top of any CNCF-compliant Kubernetes distribution.
Use Kubeflow on desktop, bare-metal, public cloud, or edge servers.
Newsletter signup
Related posts
Unlocking Edge AI: a collaborative reference architecture with NVIDIA
The world of edge AI is rapidly transforming how devices and data centers work together. Imagine healthcare tools powered by AI, or self-driving vehicles...
How to deploy Kubeflow on Azure
Kubeflow is a cloud-native, open source machine learning operations (MLOps) platform designed for developing and deploying ML models on Kubernetes. Kubeflow...
Let’s meet at AI4 and talk about AI infrastructure with open source
Date: 11 – 13 August 2025 Booth: 353 Book a meeting You know the old saying: what happens in Vegas… transforms your AI journey with trusted open source. On...