
High Availability
It is desirable to have a Charmed Kubernetes cluster that is resilient to failure and highly available. For clusters operating in public cloud environments the options and the methodology are usually straightforward - cloud providers have HA solutions which will work well in these environments, and these should be used for Charmed Kubernetes.
For 'on-premises' or private cloud deployments, there are a number of options. This documentation will present the strategies and methodology for software solutions only - if you have a hardware load-balancer, that would obviously be a better option.
We start with the two basic components of a Charmed Kubernetes cluster:
- your control plane, the
kubernetes-control-planecharm - the worker units, the
kubernetes-workercharm
Control Plane
An initial plan to make the control plane more resilient might be to simply add more
control plane nodes with juju add-unit kubernetes-control-plane:
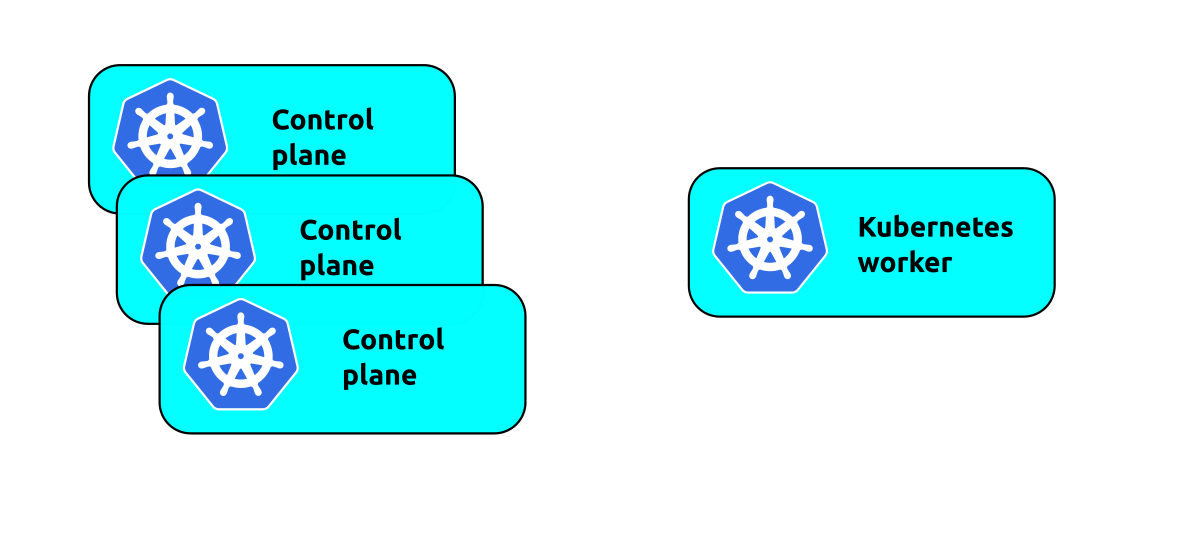
While this will add more machines, it doesn't work as may be expected. What happens is that the workers will randomly pick a control plane unit to communicate with and always use that unit. This means if that control plane unit fails in a way that doesn't remove it from Juju, those workers are simply unable to communicate with the control plane. If workers arbitrarily pick the same control plane unit, they can also overload the unit with traffic, making the additional units redundant.
Load balancing the control plane is the next logical step:
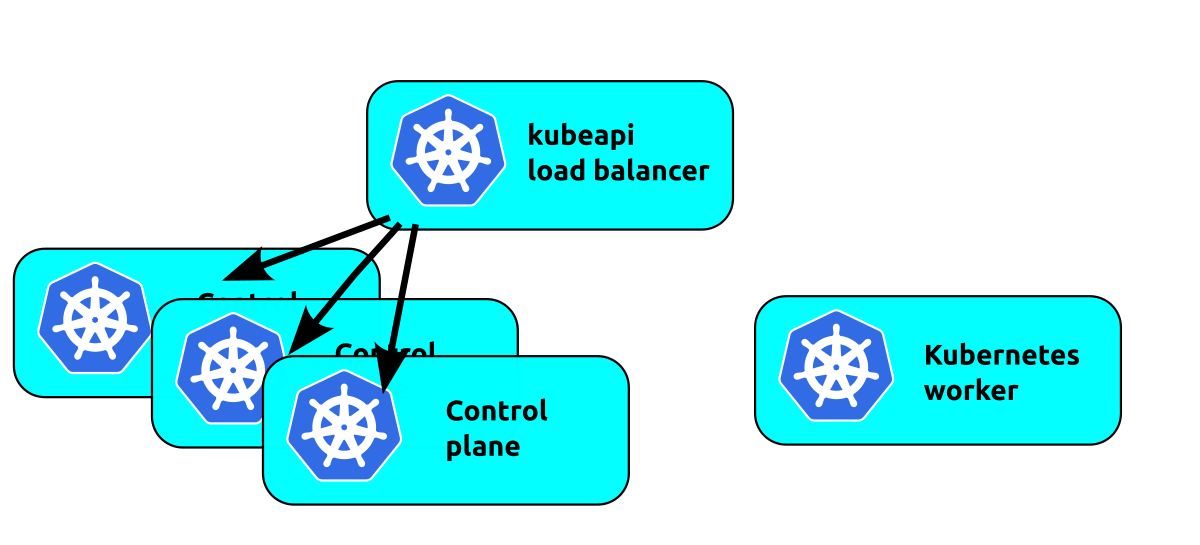
NB: The kube-api-loadbalancer is used here as a generic example. If you are running Charmed Kubernetes on a cloud such as OpenStack, AWS etc, it is usually more efficient to run a load balancer native to that cloud. See the relevant "Cloud Integration" section of the documentation for more details on your specific cloud.
The workers now all use the load balancer to talk to the control plane. This will balance the load to the control plane units, but we have just moved the single point of failure to the load balancer. Floating a virtual IP address in front of the control plane units works in a similar manner but without any load balancing. If your cluster won't generate enough traffic to saturate a single control plane, but you want high availability on the control plane, multiple control plane units floating a virtual IP address is a solid choice.
The next thought is to add multiple load balancers to add resiliency there:
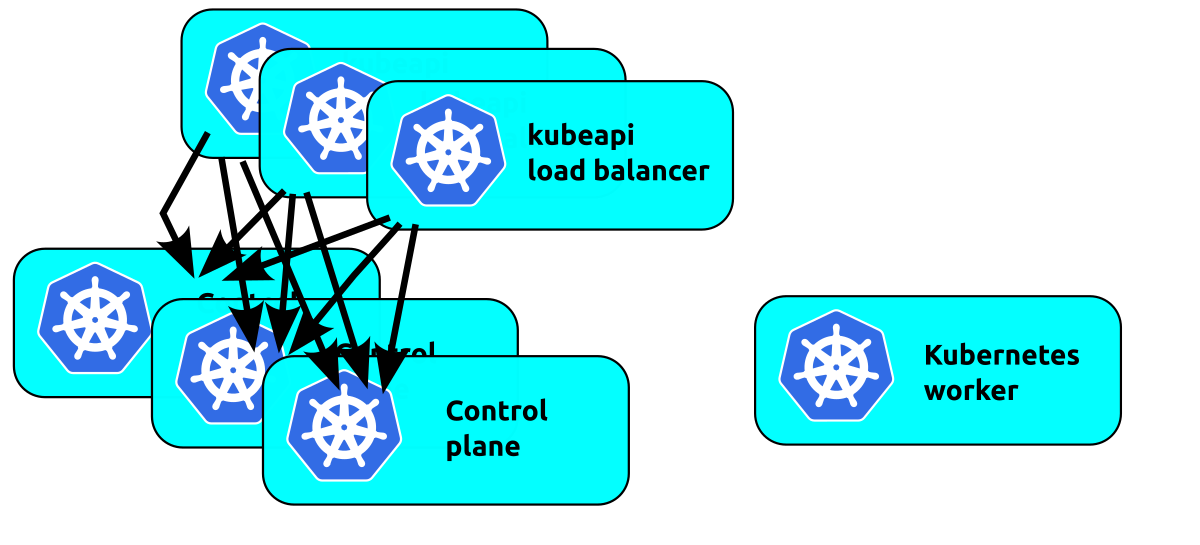
We're now back to the problem where the workers are talking to a random load balancer and if that balancer fails they will fail. We can float a virtual IP address in front of these load balancers to solve that.
The way to handle a highly available control plane is to add virtual IP addresses in front of either the control plane units or load balancers depending on load balance requirements. If the desire is simply to avoid a node failing from compromising the cluster, a virtual IP on the control plane nodes will handle that. Note that multiple virtual IP addresses can be used if load exceeds a single machine, but realise that without proper load balancing the load on the control plane units will not necessarily be even due to the random IP selection in the Kubernetes worker charms.
Worker units
Worker ingress is a very similar problem to the control plane, with the exception that the random selection of IP for the API server isn't relevant to worker ingress. There are a few ways to get traffic into Kubernetes. Two common ways are to forward incoming traffic to the service IP and route that to any worker. It will get routed by kube-proxy to a pod that will service it. The other option is to forward incoming traffic to a node port on any worker to be proxied.
Multiple virtual IPs would be a good choice in front of the workers. This allows a bit of load balancing with round-robin DNS and also allows individual workers to fail. A more robust option would be to add load balancers in front of the workers and float virtual IPs on those. Note a downside here is the increase in internal traffic as it may need to be routed due to load or just to find a worker with the correct destination pod. This problem is under active development with projects that are Kubernetes-aware such as MetalLB.
Solutions
The pages linked below give practical details on how to use the currently supported software to enable HA
See the guide to contributing or discuss these docs in our public Slack channel.