
%27%20fill%3D%27%23E95420%27%3E%3Cpath%20d%3D%27m15.839%205.293-1.447-2.8a.136.136%200%200%200-.051-.055.144.144%200%200%200-.074-.02h-5.8a.143.143%200%200%200-.091.03.13.13%200%200%200-.034.17.138.138%200%200%200%20.072.06l7.251%202.8a.144.144%200%200%200%20.17-.054.13.13%200%200%200%20.007-.13l-.003-.001ZM11.839%204.945.073.223A.073.073%200%200%200%20.026.221a.07.07%200%200%200-.038.027.065.065%200%200%200%20.007.086l7.962%208.182a.069.069%200%200%200%20.049.022.072.072%200%200%200%20.047-.019l3.805-3.461a.066.066%200%200%200%20.02-.061.065.065%200%200%200-.014-.03.07.07%200%200%200-.028-.02l.003-.002ZM5.382%207.183a.071.071%200%200%200-.062-.022.07.07%200%200%200-.03.011.067.067%200%200%200-.023.025l-4.13%207.696a.065.065%200%200%200-.005.046.068.068%200%200%200%20.027.038.072.072%200%200%200%20.09-.006L7.13%209.18a.066.066%200%200%200%200-.087l-1.75-1.91Z%27%2F%3E%3C%2Fg%3E%3Cdefs%3E%3CclipPath%20id%3D%27a%27%3E%3Cpath%20fill%3D%27%23fff%27%20d%3D%27M0%200h15.83v15.21H0z%27%2F%3E%3C%2FclipPath%3E%3C%2Fdefs%3E%3C%2Fsvg%3E)

%27%20fill%3D%27%23E95420%27%3E%3Cpath%20d%3D%27M1.936%202.592c.668%200%201.21-.515%201.21-1.151S2.604.29%201.936.29C1.267.29.726.805.726%201.44c0%20.637.541%201.152%201.21%201.152ZM14.56.576H3.404a1.587%201.587%200%200%201%20.024%201.69l-.026.04h11.156a.56.56%200%200%200%20.386-.15.518.518%200%200%200%20.16-.369v-.692a.502.502%200%200%200-.16-.369.543.543%200%200%200-.386-.15ZM1.936%206.701c.668%200%201.21-.515%201.21-1.15%200-.637-.542-1.152-1.21-1.152-.669%200-1.21.515-1.21%201.151s.541%201.151%201.21%201.151ZM14.56%204.685H3.404a1.612%201.612%200%200%201%20.242%201.083c-.03.215-.105.421-.219.608l-.026.04h11.157a.56.56%200%200%200%20.386-.15.518.518%200%200%200%20.16-.37v-.692a.5.5%200%200%200-.16-.369.542.542%200%200%200-.386-.15ZM1.936%2010.81c.668%200%201.21-.515%201.21-1.15%200-.637-.542-1.152-1.21-1.152-.669%200-1.21.515-1.21%201.151s.541%201.151%201.21%201.151ZM14.56%208.795H3.404a1.611%201.611%200%200%201%20.243%201.082%201.581%201.581%200%200%201-.245.648h11.156a.559.559%200%200%200%20.386-.15.517.517%200%200%200%20.16-.37v-.692a.502.502%200%200%200-.16-.368.543.543%200%200%200-.386-.15ZM1.936%2014.92c.668%200%201.21-.515%201.21-1.15%200-.637-.542-1.152-1.21-1.152-.669%200-1.21.515-1.21%201.151s.541%201.151%201.21%201.151ZM14.56%2012.904H3.404a1.611%201.611%200%200%201%20.242%201.082%201.58%201.58%200%200%201-.219.608l-.026.04h11.157a.562.562%200%200%200%20.386-.15.517.517%200%200%200%20.16-.37v-.692a.5.5%200%200%200-.16-.369.543.543%200%200%200-.386-.15Z%27%2F%3E%3C%2Fg%3E%3Cdefs%3E%3CclipPath%20id%3D%27a%27%3E%3Cpath%20fill%3D%27%23fff%27%20d%3D%27M0%200h15.83v15.21H0z%27%2F%3E%3C%2FclipPath%3E%3C%2Fdefs%3E%3C%2Fsvg%3E)
%27%20fill%3D%27%23E95420%27%3E%3Cpath%20d%3D%27M9.618.272c-.634%200-1.243.243-1.691.674-.448.43-.7%201.015-.701%201.624v4.221a1.9%201.9%200%200%201%201.362%200v-4.22a.955.955%200%200%201%20.291-.72%201.067%201.067%200%200%201%201.479%200%20.955.955%200%200%201%20.29.719v.962h1.363V2.57c0-.61-.253-1.194-.702-1.625A2.445%202.445%200%200%200%209.618.272ZM9.017%208.433c0%20.21-.065.417-.187.593a1.102%201.102%200%200%201-.499.393c-.203.08-.426.102-.642.06a1.125%201.125%200%200%201-.568-.292%201.055%201.055%200%200%201-.304-.547%201.028%201.028%200%200%201%20.064-.616c.084-.195.226-.362.41-.479a1.143%201.143%200%200%201%201.401.133c.103.1.185.217.24.347.057.129.085.268.085.408ZM2.773%205.855c-.634.001-1.242.244-1.69.674C.633%206.96.381%207.545.38%208.154v4.082a1.901%201.901%200%200%201%201.363%200V8.154a.955.955%200%200%201%20.29-.719%201.067%201.067%200%200%201%201.479%200%20.955.955%200%200%201%20.29.719v.962h1.363v-.962c0-.61-.253-1.194-.702-1.625a2.444%202.444%200%200%200-1.69-.674ZM2.166%2013.878c0%20.21-.065.415-.186.59-.121.174-.294.31-.496.39-.202.08-.424.102-.638.06a1.119%201.119%200%200%201-.565-.29%201.049%201.049%200%200%201-.302-.543c-.043-.206-.02-.42.063-.614.084-.194.225-.36.407-.476a1.136%201.136%200%200%201%201.394.133%201.024%201.024%200%200%201%20.323.75Z%27%2F%3E%3Cpath%20d%3D%27M14.752%204.76a1.789%201.789%200%200%201-.681-.126v2.411a.972.972%200%200%201-.312.682c-.193.179-.45.28-.718.28-.268%200-.526-.101-.718-.28a.972.972%200%200%201-.312-.682V4.32h-1.363v2.726c0%20.61.252%201.195.7%201.626a2.443%202.443%200%200%200%201.692.673c.635%200%201.244-.242%201.692-.673.449-.431.7-1.016.7-1.626v-2.41a1.9%201.9%200%200%201-.68.125ZM15.858%202.822c.037.225%200%20.455-.107.658a1.1%201.1%200%200%201-.49.472%201.161%201.161%200%200%201-1.302-.198%201.04%201.04%200%200%201-.206-1.251%201.1%201.1%200%200%201%20.492-.47%201.161%201.161%200%200%201%201.299.199c.166.16.276.366.314.59ZM7.907%2010.2c-.233%200-.465-.042-.681-.126V12.6a.97.97%200%200%201-.302.7%201.05%201.05%200%200%201-.728.29%201.05%201.05%200%200%201-.728-.29.97.97%200%200%201-.302-.7V9.845H3.804V12.6c0%20.61.252%201.194.7%201.625a2.443%202.443%200%200%200%201.692.674c.634%200%201.243-.243%201.692-.674.448-.43.7-1.015.7-1.625v-2.526a1.887%201.887%200%200%201-.68.127Z%27%2F%3E%3C%2Fg%3E%3Cdefs%3E%3CclipPath%20id%3D%27a%27%3E%3Cpath%20fill%3D%27%23fff%27%20d%3D%27M0%200h15.83v15.21H0z%27%2F%3E%3C%2FclipPath%3E%3C%2Fdefs%3E%3C%2Fsvg%3E)

Introducing Turku: Cloud-Friendly Backups for Your Infrastructure

Ryan Finnie
on 4 August 2015
It’s a topic many people don’t like to think about: backups. In addition to making sure your cloud environments are correctly deployed, highly available, secured and monitored, you need to make sure they are backed up for disaster recovery purposes. (And no, replication is not the same as backups.)
Canonical’s IS team is responsible for thousands of machines and instances, and over the years we have been a part of the shift from statically-deployed bare-metal environments to embracing dynamic environment deployments on private and public clouds. As this shift has occurred, we’ve needed to adjust our thinking about how to back up these environments. This has led to the development of Turku, a decentralized, cloud- and Juju-friendly backup system.
Old and Busted
Traditional backup systems tend to follow a similar deployment workflow:
- A backup agent is installed on the machine to be backed up.
- A centralized server is configured with information about the client machine, what to back up, and when.
- At scheduled times, the server connects to the client agent and performs backups.
This workflow has several disadvantages. Primarily, it relies on a centralized configuration mechanism. This may be fine if you only have a few static machines to back up, but the act of manually configuring backups on a backup server does not scale well.
In addition, most backup systems require ingress access to the machine to be backed up. While this may seem logical at first, it becomes a problem when the concept of the service unit is no longer tightly coupled to a machine’s hostname or IP. Not to mention the security aspect of allowing one machine direct access to all of your infrastructure.
Most of our environments are deployed via Juju, which abstracts the concept of networking, especially for services which are not at the front-end layer and do not have floating IPs. Your typical database / store unit is never going to have a floating IP, in most cases is not reachable from most of our networks, and in some cases isn’t even likely to be in the same location tomorrow. Having a backup server being able to reach this sort of unit is usually just not possible.
New Hotness
After struggling with the limitations of these sorts of backup systems, Canonical’s IS team put together a decentralized, cloud-friendly backup system called Turku. Turku takes a different approach to backup management:
- A backup agent (turku-agent) is installed on the machine to be backed up. This can be installed manually, or be deployed as a Juju subordinate service.
- The agent is configured with the location and API key of an API server (turku-api), and with sources of data to be backed up (where, when, what to exclude, how long to keep snapshots, etc). In a Juju subordinate charm setup, this is as easy as the master charm dropping configuration files in /etc/turku-agent/sources.d/ and running
turku-update-config. - The agent registers itself with the API server and sends its configuration. It then regularly checks in with the API server (every 5 minutes by default). If the API server determines it’s time for a backup (using scheduling data provided by the agent), it tells the agent to check in with a particular storage unit (turku-storage).
- The agent checks in with the storage unit by SSHing to it, using a unit-specific public key relayed from the agent to the storage unit via the API server. This SSH session includes a reverse tunnel to a local Turku-specific rsync daemon on the agent machine.
- The storage unit connects to this rsync daemon over the reverse tunnel and rsyncs the scheduled data modules. It then handles snapshotting of the data. The preferred method is using attic, a deduplication program, but it can also use hardlink trees or even no snapshotting, depending on the nature of the source of data to be backed up.
- Storage units occasionally expire snapshots using retention policies, again, as configured by the agent.
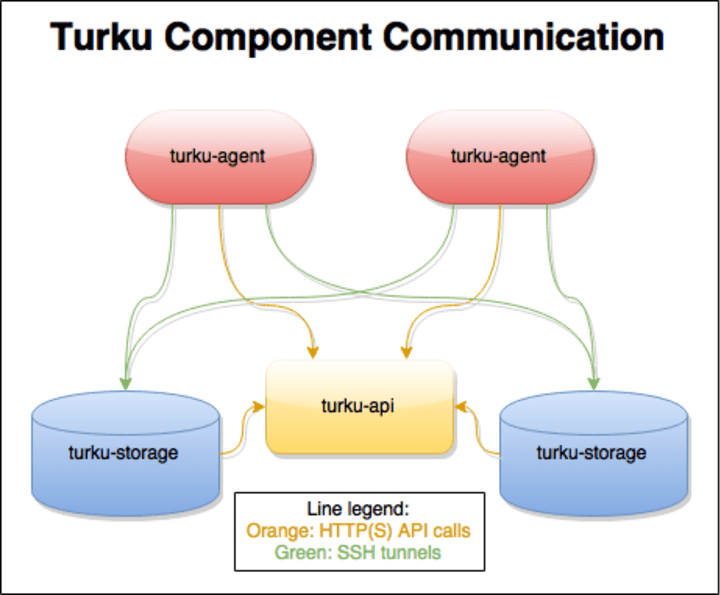
This workflow gives most of the power to the client, and avoids needing to configure a centralized server every time a client unit is added or removed. In almost all situations, no configuration is needed on any server systems. And because of the reverse tunnel, no ingress access is required to each client machine; only egress to the API server and storage units are required.
Schedule and retention information is defined in the agent using natural language expressions. For example, a typical daily backup source may be configured with the schedule “daily, 0200-1400”. As we have thousands of machines being backed up, we found that it’s best to configure the source with a schedule as wide as possible, to allow the API server’s scheduler the most freedom to determine when a backup should start. In most cases, service units are not time-constrained, so most schedule definitions are simply “daily”.
You can be specific, such as “sunday, 0630” for a weekly run, and the API scheduler will try to be as accommodating as possible, but again, it’s recommended to be as open as possible when it comes to backup times.
Similarly, a typical retention definition is “last 5 days, earliest of 1 month, earliest of 2 months”. For example, if today is December 15 and a backup is made, 7 snapshots would exist: December 11 through 15, December 1 and November 1.
Restores
A backup system is useless if you can’t be confident you can restore the data. When Turku was handed over to the IS Operations team to begin deployment and migrations from our previous backup systems, the first thing they did was test restores in a variety of situations. They came up with some interesting scenarios and helped improve usability of the restore mechanism.
In most cases, when doing a restore, you usually don’t want to restore in place. At first this seems counter-intuitive, but when dealing with a disaster recovery situation, it’s usually a matter of getting data from a previous point in time and re-integrating it with the live data in some way, depending on the exact nature of the disaster.
You may remember from above that the Turku agent runs its own local rsync daemon which is served over the reverse SSH tunnel. Most of this daemon’s modules are read-only sources of data to be backed up, but it also includes a writable restore module. When you run “turku-agent-ping –restore” on the machine to restore data to, it connects to the storage unit and establishes the reverse tunnel as normal, but then just sits there until cancelled. You then log into the storage unit, pick a snapshot to restore, then rsync it to the writable module over the tunnel. (As the tunnel ports and credentials are randomized, “turku-agent-ping –restore” helpfully gives you a sample rsync invocation using the actual port/credentials.) This is one of the only times you’ll need to log into a Turku infrastructure machine, but it gives the administrator the most flexibility, especially in a time of crisis.
Scalability
Turku is designed for easy scale-out when deployed via Juju. turku-api is a standard Django application and can be easily horizontally scaled through juju add-unit turku-api (though in practice we’ve had thousands of units checking in to a pair of turku-api units with almost no load). turku-storage is also horizontally scalable, which is more important as your backup infrastructure grows. To expand storage, you can simply add more block storage to an existing turku-storage unit (they’re managed in an LVM volume on each unit), or add more units with juju add-unit turku-storage, plus block storage.
When more storage is added to Turku, either through raw block storage or new storage units, the API scheduler automatically takes care of proportionally allocating new agents/sources depending on the storage split. For example, if you have two 5TB turku-storage units, one of which is half full and the other is empty, a new registered source will be twice as likely to be assigned to the empty storage unit. When storage units reach an 80% high water mark, they stop accepting new sources altogether, but will continue to back up existing registered sources. Actively rebalancing storage units is not currently supported as the proportional registration system plus the high water mark is sufficient for most situations, but it is planned for the future.
Current Status
Most of our backup infrastructure has been migrated to Turku, which has been in operation for approximately 6 months. We’re releasing the code in the state we have been using it, but this is a very early public release. Documentation will be ported over from our internal wikis, and it’s possible there is code or functionality specific to our infrastructure (though unlikely, as Turku was developed with the goal of eventually being open sourced).
Please take a look at the Turku project page on Launchpad, download the software, take a look, file bugs… We’re excited to hear from you!
N.B.: Turku is a city on the southwest coast of Finland at the mouth of the Aura River, in the region of Finland Proper. To the Swedes, it is known by its original Latin name: Åbo, or Aboa. One of Canonical’s first server naming schemes over 10 years ago was Antarctic bases, and our first backup server was aboa, named after the Finnish research station. Backup systems since then have tended to be a play on the name Aboa.
Smart operations, optimal architecture, better pricing.
OpenStack and Ubuntu bring automated deployment and management that help you optimise infrastructure costs — no matter your industry or use case.