
Patterns to achieve database High Availability

Mohamed Wadie Nsiri
on 2 August 2022
Tags: data ops , data platform , Database , high availability , MySQL , NoSQL , PostgreSQL , RDBMS
The cost of database downtime
A study from ManageForce estimated the cost of a database outage to be an average of $474,000 per hour. Long database outages are the result of poor design concerning high availability.
With the exponential growth of data that is generated over the internet (which is expected to reach 180 zeta-bytes by the end of 2025) and the increasing reliance on different database technologies to serve those data to their intended users, the cost of database downtime will continue to increase in the upcoming years.

This blog will first expose the main concepts around availability. Then, we will list some of the patterns to provide highly available database deployments and finish by explaining how Canonical solutions help you in deploying highly available applications.
High level concepts
Before going into the details of how to achieve high availability for databases, let’s ensure that we have a common understanding of a few concepts.
Availability and Durability
Availability is a measure of the uptime of a given service over a period of time. It can be understood as the opposite of downtime. For example, a monthly availability of 99,95% implies a maximum downtime of about 22 minutes per month.
Durability is a measure of the ability of a given system to preserve data against certain failures (e.g. hardware failure). For example, a yearly durability of 99.999999999% implies that you might lose one object per year for every 100 billion objects you store !
Note that data availability and data durability are quite different. You might be unable to access the data during a database outage but you still expect the persisted data to be reachable when the database is up again.
Compute and Storage
In the rest of this blog, I will use instance to refer to the compute part of a database deployment in a given host. The instance is the interface to which the database client connects.
Besides, I will use the term database to refer to the storage part, essentially the data “files”, managed by the associated instance(s).
Note that the instance and the database can reside in different hosts.
Patterns to achieve database high availability
High availability is typically achieved using redundancy and isolation constructs. Redundancy is implemented by duplicating some of the database components.Isolation is achieved by placing the redundant components in independent hosts.
The term cluster refers to the entirety of the components of a database deployment, including its redundant ones. Together, these components ensures the availability of the solution.
Let’s explore in the next section some of the clustering patterns.
Redundancy/Clustering constructs
As we saw earlier, there are 2 main parts of a database deployment that we can make redundant to achieve high availability:
- Database instance, which refers to the compute part.
- Database, which refers to the storage part.
Instance-level clustering
In this type of clustering, we protect the database instance part by deploying several instances in different hosts. The database resides, typically, on a remote storage visible to all the concerned hosts.
We can have 2 types of instance-level clustering:
- Active/Active type where the instances are actively processing database clients requests in parallel. This is the case of Oracle database’s Real Application Cluster. When there is an issue with one instance, the database clients requests will be routed to the remaining, healthy instances.
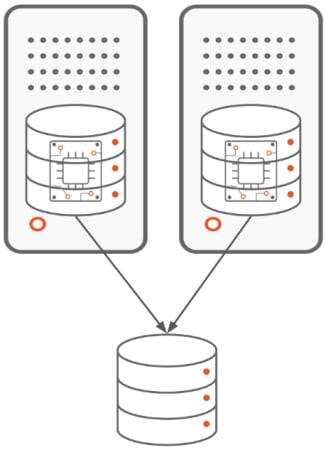
- Active/Passive type where, at any given time, there is only one instance actively processing database clients requests. When there is an issue with the old active instance, the clients requests will be transferred to the newly elected active instance. Microsoft SQL Server’s Failover Cluster Instance (FCI) and Veritas’s Cluster Server offer this kind of clustering.
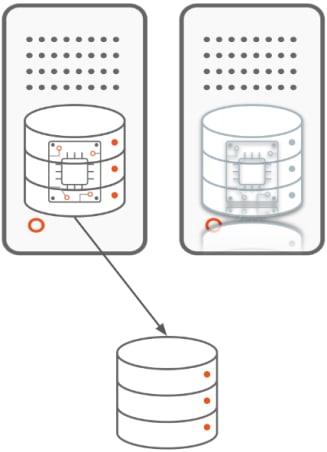
Database-level clustering
In this type of clustering, we protect both the database instance and the database. Protecting only the database might result in a situation where your data is protected but there is no way to access it quickly.
Note that we can create offline copies of the database for backup purposes. Yet, the main purpose, in such a case, is data protection.
The high availability of the database is achieved through replication. We can distinguish 2 types of replication depending on the layer performing it:
- Storage-based replication, where a storage/filesystem level protocol pushes the changes happening in one database to the other databases. This is the type of clustering offered by the combination of Microsoft SQL Server’s Failover Cluster Instance (FCI) and Storage Space Direct. In this type of replication, the additional instances are typically on standby mode and the replication protocol is usually synchronous.
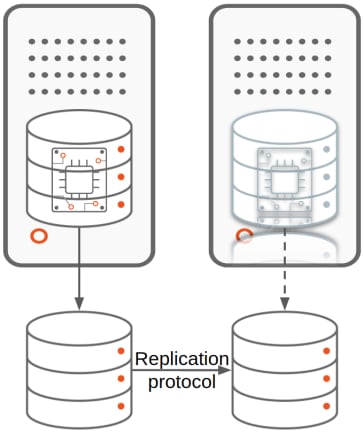
- Database solution-based replication, where a database level protocol pushes the changes happening within one database to the other databases. This is the kind of clustering provided by solutions like MongoDB’s ReplicaSet, Microsoft SQL Server’s AlwaysOn Availability Group and Oracle database’s Data Guard. We can have 2 subtypes for database solution-based replication:
- Logical replication: where we replicate the database client requests from one instance to the other. Oracle Golden Gate and MySQL statement based replication support this type of replication.
- Physical replication: where we replicate the effect of database client requests on the data from one database to the other (going through the instance). Oracle Data Guard and MySQL row based replication support this kind of replication.
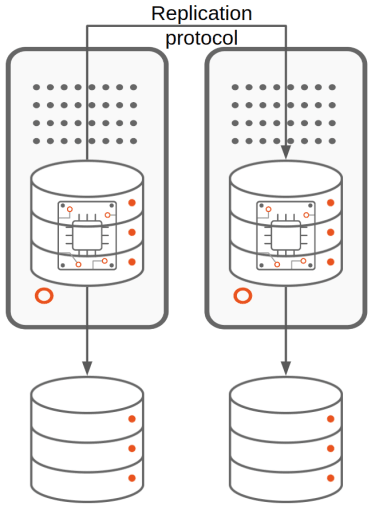
We use the term replicas to denote the additional database(s) resulting from the replication mechanism.
The primary database/instance is the one receiving the client’s write traffic.
Shared-nothing database deployments are composed of independent servers, each having its own dedicated memory, compute and storage. They tend to provide higher availability as they allow us to leverage all the isolation constructs we will see in the next section.
Isolation constructs
Isolation is about reducing the impact radius of a given failure/disaster event on your cluster components . The more distant your redundant components are, the less likely that all of them will fail simultaneously.

Server isolation
This is the most elementary form of isolation. Placing redundant components in different servers prevents a failure in a network card, an attached storage device or a CPU from impacting all of your redundant components.
Rack isolation
A rack is a standardised enclosure to mount servers and various other electronic equipment. The servers hosted in the same rack might share a number of elements like network switches and power cables. Placing your redundant components into servers hosted in different racks will prevent a failure on one of the rack-shared components from impacting all of your deployment.
Data centre isolation
Typically, all the servers hosted in a given data centre share power and cooling infrastructures. Using several data centres to host your database deployment will make it resilient towards a broader range of events, like power failures and data centre-wide maintenance operations.
Availability zone isolation
Public cloud providers popularised the concept of “availability zone”. It consists of one or more data centres that are, geographically speaking, close to each other.
Using several availability zones to host your database deployments might protect your services from some “natural” disasters like a fire and floods.
Region isolation
We can go one step further in terms of isolation and use several regions for our database deployments. This kind of set-up can protect your database from major disasters like storms, volcano eruptions and even political instability (think about transferring your workload from a war zone to another region).
Now that we have a good overview on how to make a given database deployment resilient to certain failure events, we need to make sure that we can automatically leverage its resiliency.
Automatic fail-over management
Fail-over is the process by which we transfer ownership of a database service from a faulty server to a healthy one.
A fail-over can be initiated manually by a human or automatically by a component of the database deployment. Relying on human intervention might result in higher downtime compared to automated fail-overs, therefore it should be avoided.
Server side fail-over
In order to automatically initiate a fail-over from a primary instance/database to a replica, a component should monitor the state of each of the instances and decide to which healthy one the service should be transferred.
Here is a list of fail-over tools for some of the popular databases:
- Orchestrator for MySQL/MariaDB
- Patroni (including the required Distributed Configuration Store) for PostgreSQL
- Windows Server Failover Cluster (WSFC) including participant voting witnesses for SQL Server
- Oracle Data Guard (including the observers component) for Oracle database
If you are planning to use such tools then you need to perform a series of tests (both on primary and replicas) to ensure that the cluster behaviour matches your expectations:
- Gracefully stop the main database instance process
- Abruptly kill the main database instance process
- Reboot the hosting server
- Kill the clustering/fail-over processes
- Isolate, from network perspective, the concerned database instance from the rest of the database instances
Depending on the behaviour of the chosen solution, you might need to implement your own customisation to meet your requirements.
Application side fail-over
An important aspect, often overlooked, in database high availability is the capacity of the application to promptly (re)connect to the healthy database instances following a server fail-over.
In order for your applications to fail-over quickly to the healthy instances, you might need to:
- Set reasonable TCP keepalive settings that allow your applications to detect broken connections on-time.
- Set time-outs on all your database calls to avoid hanging connections.
- Implement retry logic within your applications to mitigate certain types of database/network errors.
- Use database proxies to hide changes of the primary host from the database client.
As we saw during the previous section, ensuring database high availability involves a considerable amount of work to design, test and maintain several components and configurations.
In the next section, we will talk about the Canonical offerings that can help you reach your high availability goals.
Canonical solution to provide High Availability
Juju is the Canonical’s answer to automatically manage complex applications involving any number of technologies, including databases.
We provide a curated list of charmed Juju operators for a wide range of databases with built-in high availability and fail-over automation.
Moreover, Juju’s unique ability to express relations between various workloads helps you in ensuring, for example, that your application will always target a healthy database instance.
Juju helps DevOps, DBAs and SREs in quickly deploying, maintaining and upgrading applications in a holistic fashion.
The Juju ecosystem allow its users to retain a high degree of customization and freedom:
- We provide open source operators that you can customise and extend at will.
- You can decide to retain full access to the underlying infrastructure or let us manage the infrastructure for you.
- Juju can deploy your applications on several clouds, giving you the freedom to choose what best fits your needs.
Please contact us to learn more about Juju and our solutions to achieve high availability for your workloads.
Ubuntu cloud
Ubuntu offers all the training, software infrastructure, tools, services and support you need for your public and private clouds.
Newsletter signup
Related posts
Should you use open-source databases?
You are not the only one asking this seemingly popular question! Several companies are torn between the rise in appeal of open-source databases and the...
How to secure your database
Cybersecurity threats are increasing in volume, complexity and impact. Yet, organisations struggle to counter these growing threats. Cyber attacks often...
SQL vs NoSQL: Choosing your database
IT leaders, engineers, and developers must consider multiple factors when using a database. There are scores of open source and proprietary databases...