
#MadeWithJuju: Apache Analytics SQL

James Donner
on 25 November 2015
With last week’s announcement of Autopilot GA, we’re making the installation of OpenStack easier than ever. But once you’ve deployed OpenStack using our Autopilot tool, what’s next?
Have you considered Juju for Big Data? Canonical’s service modeling tool allows you to deploy cloud services in seconds. With Big Data on the rise, Juju is becoming a fast and easy platform for making it come to life. In this blog, we’ll take a quick look at the Apache Analytics SQL bundle available in the Juju Charm Store.
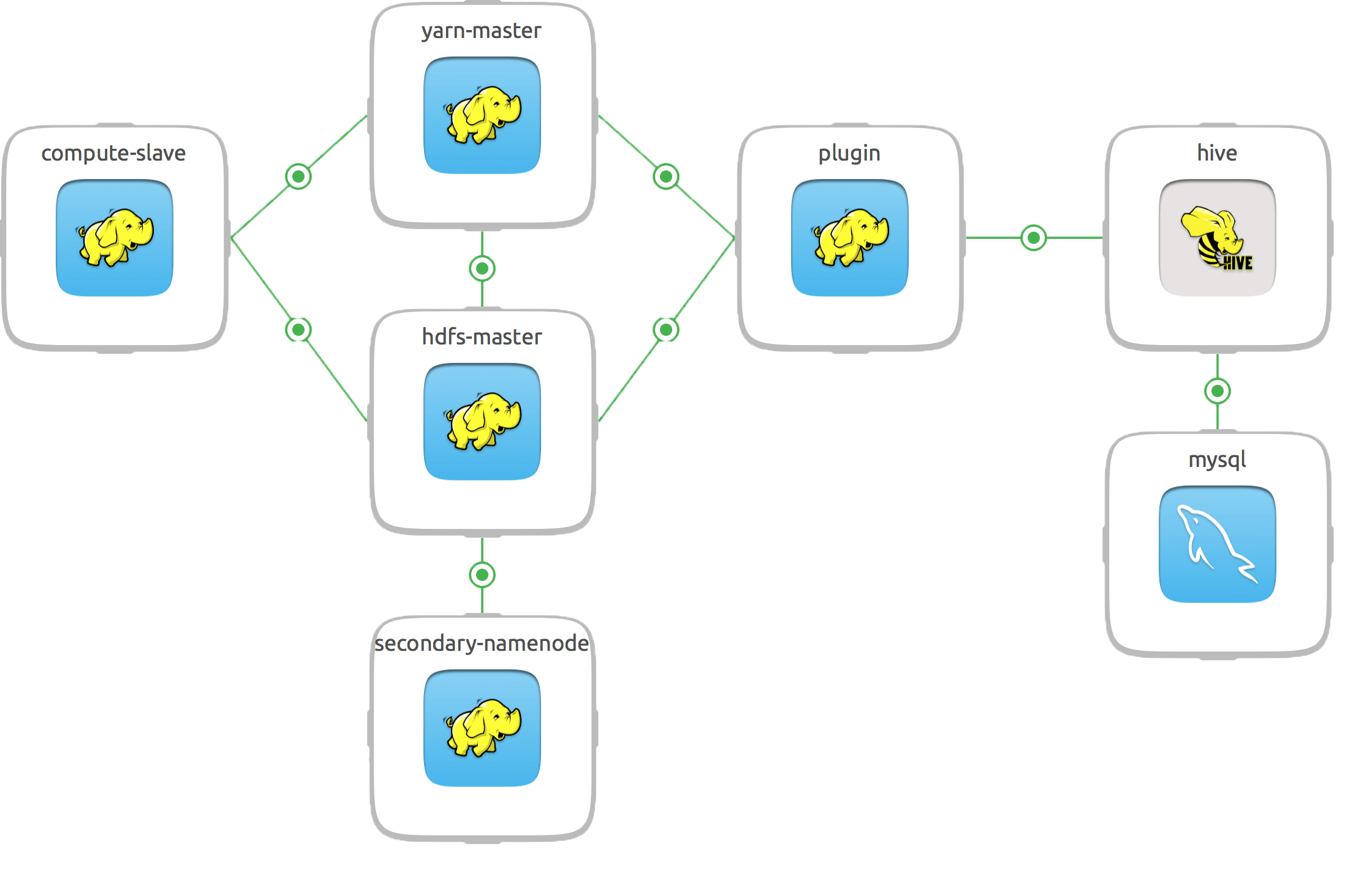
Let’s walk through how this solution works. We begin at the Apache Analytics with SQL bundle. This is an 8 node cluster designed to scale out. This contains 1 HDFS master, 1 HDFS secondary namenode, 1 YARN master, 3 compute slaves, and 1 plugin colocated onto the connecting hive unit. The Hive charm to the right represents the data infrastructure built on top of Hadoop. This will let you design your tables and file distributions in order to effectively warehouse the data. Hive then uses MySQL to store the metadata about the table views of the data stored in HDFS.
So why should you use Juju? Instead of going through the long process of manually setting up your services, Juju lets you drag and drop your perfect solution and build your relations across charms. Spend less time deploying and more time doing. With Juju’s charm store allowing for flexibility and bundles making service modeling easy, the only question is what you will do with Juju.
We can’t wait to show you what else can be #MadeWithJuju in our new blog series, so stay tuned for more unique use cases to learn what you can do with Juju. Want to take Juju for a test drive? Try it from the comfort of your web browser. Or if you’re ready to get started, here’s all the information you need.
Talk to us today
Interested in running Ubuntu in your organisation?
Newsletter signup
Related posts
Charmed MySQL enters General Availability
Nov 6th, 2024: Today Canonical announced the release of Charmed MySQL, an enterprise solution that helps you secure and automate the deployment, maintenance...
Cut data center energy costs with bare metal automation
Data centers don’t have to be power-hungry monsters. With smart automation using tools like MAAS, you can reduce energy waste and operational costs, and make...
The hitchhiker’s guide to infrastructure modernization
One of my favourite authors, Douglas Adams, once said that “we are stuck with technology when what we really want is just stuff that works.” Whilst Adams is...