
The Road to Kubernetes & vSphere Integration

Kevin W Monroe
on 23 August 2018
Tags: Charmed Kubernetes , containers , Juju , juju resource , kubernetes , VMware , vSphere
This article on Kubernetes & vSphere integration originally appeared at Kevin Monroe’s blog
Background
Recently, Juju began supporting cloud-native features via “integrator” charms (e.g.: aws-integrator, gcp-integrator, openstack-integrator). These allow charms to request things like persistent storage from a cloud provider without having to shuffle your super-secret credentials around to all the applications in your deployment.
The way an integrator charm works is simple: you entrust it (and only it) with your Juju credentials for a particular cloud and then relate it to charms that want to make cloud-native requests. The integrator will ensure appropriate roles are created, submit a request to the cloud, and then notify the requesting charm that enough data is available to start using the new resource. Lately I’ve been testing Canonical Kubernetes (CDK) on the VMware vSphere platform — to Juju, vSphere is supported like any other cloud. I really needed persistent storage for my pods and thought, “it sure would be nice if there was a vsphere-integrator that I could use for this.” So I wrote one.
In this post, I’ll share how the vsphere integrator came to be, and more importantly, how others that want native vSphere integration with charms can use it.
Last things first
If I’ve learned anything from watching videos like “how do I quickly turn off the water to my toilet?”, it’s that people want results first.
Here are the source repos that enable vSphere integration with charms:
- interface-vsphere-integration: this is how communication flows between the integrator and requestor.
- charm-vsphere-integrator: this is the integrator itself. It listens for requests and sets flags so that requestors know when resources are available.
And here’s the deployable integrator charm:
- vsphere-integrator: built charm released to the charm store.
Using the integrator is straightforward. First, bootstrap a vSphere cloud if you haven’t already done so:
Then, deploy vsphere-integrator and trust it with your vSphere credentials:
juju deploy ~containers/vsphere-integrator juju trust vsphere-integrator
Note: juju trust works in Juju 2.4 and above. If you’re using an earlier version, or prefer to see other ways to set credentials on the integrator, have a look at the integrator’s readme.
At this point, the integrator is waiting to handle requests from related charms. Since this is so new, the only workloads that support the vsphere-integration interface are kubernetes-master and kubernetes-worker. If you’d like to enable other workloads, check out the interface docs to see what charm modifications are needed.
Let’s see the integrator in action with a Kubernetes workload.
K8s + vSphere, better together
Prerequisites
- vSphere cloud bootstrapped with Juju 2.4 or greater. Here’s the doc link mentioned above for help with this.
- This work is based on the upcoming K8s 1.12 release; without a doubt, it will not work on earlier K8s releases. Welcome to the edge.
- In vSphere, we need to set
disk.enableUUID = trueas a VM Option on our VMs so that the K8s vSphere provider knows how to map persistent volumes to machines. You can do this for all VMs by using a VM template, or do it per machine. See the vSphere docs for details.
Deploying
Since K8s 1.12 hasn’t been released yet, we’ll need to modify a bundle to use the 1.12 beta bits for deployment. Here’s a hunk of yaml that we can overlay to do just that:
applications:
kubernetes-master:
options:
channel: 1.12/beta
kubernetes-worker:
options:
channel: 1.12/beta
vsphere-integrator:
charm: cs:~containers/vsphere-integrator
num_units: 1
relations:
- ['vsphere-integrator', 'kubernetes-master']
- ['vsphere-integrator', 'kubernetes-worker']
Save the above to overlay.yaml and deploy like this (Note: the same overlay will work for both canonical-kubernetes and kubernetes-core):
## deploy a k8s bundle with our overlay juju deploy cs:canonical-kubernetes --overlay /path/to/overlay.yaml ## trust the integrator with your vsphere credentials juju trust vsphere-integrator
Note: for those that just skimmed the prereqs, you need to set disk.enableUUID = true as a VM Option on our VMs so that the K8s vSphere provider knows how to map persistent volumes to machines. You can do it for the kubernetes-master and -worker machines that you just deployed, but you’ll have to turn them off and on again for the VM Option to take effect. See the vSphere docs for details.
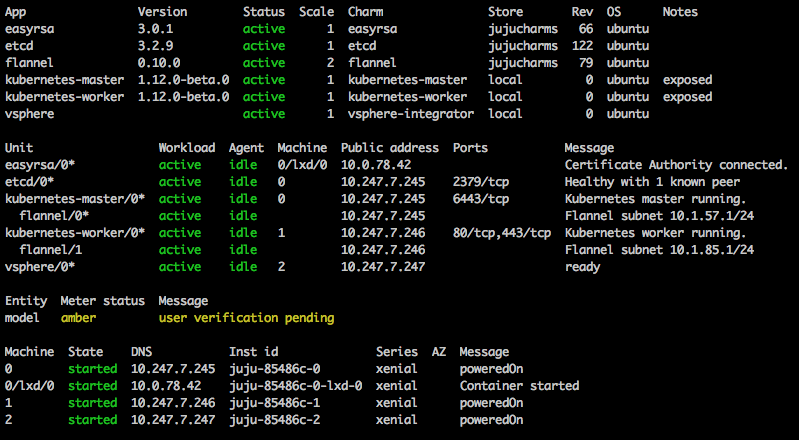
Once the deployment settles, juju status should look similar to this:
Verify persistent storage
With deployment complete, let’s define a Storage Class and Persistent Volume Claim so our pods can dynamically request Persistent Volumes from vSphere:
## for this example, interact with kubectl on the k8s master
juju ssh kubernetes-master/0
## create our storage class
kubectl create -f - <<EOY
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: mystorage
provisioner: kubernetes.io/vsphere-volume
parameters:
diskformat: zeroedthick
EOY
## create a persistent volume claim using that storage class
kubectl create -f - <<EOY
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: testclaim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Mi
storageClassName: mystorage
EOY
Let’s make sure those were created successfully:
kubectl get sc mystorage NAME PROVISIONER AGE mystorage kubernetes.io/vsphere-volume 26h kubectl get pvc testclaim NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE testclaim Bound pvc-xxx 100Mi RWO mystorage 26h
Next, create a pod (busybox in this case) that wants a pv based on the above claim:
kubectl create -f - <<EOY
apiVersion: v1
kind: Pod
metadata:
name: busybox
namespace: default
spec:
containers:
- image: busybox
command:
- sleep
- "3600"
imagePullPolicy: IfNotPresent
name: busybox
volumeMounts:
- mountPath: "/pv"
name: testvolume
restartPolicy: Always
volumes:
- name: testvolume
persistentVolumeClaim:
claimName: testclaim
EOY
And finally, get a microphone, drop it, and tell your friends how your busybox pod has all the persistent megabytes:
kubectl exec busybox -- df Filesystem 1K-blocks Used Available Use% Mounted on ... /dev/sdb 95054 1550 91456 2% /pv ...
Read on for details on what just happened!
Behind the curtain
The interface and charm parts of vsphere-integrator were super simple to implement. In fact, I just forked the openstack-integrator and interface-openstack-integration repos and did a big ‘ol insensitive sed /openstack/vsphere/g to get the PoC going. The most significant changes were getting the language right (an OpenStack project roughly maps to a vSphere datacenter, etc).
At the end of the day, all an integrator charm does is ensure roles are present and a requestor can make a request. The roles part is a no-op since a vSphere credential is an admin for your cluster; trusting vsphere-integrator means it can do anything an admin can do. Once trusted, the vsphere-integrator simply tells your K8s charms that it can provide enough details for them to start making requests.
The harder part was on the K8s side. If you’ve ever searched for K8s/vSphere integration guides, you know the frustration of figuring out whether a cloud config option is valid for your particular version of K8s. As mentioned earlier, all these bits assume you’re on K8s 1.12 or greater. Why? Because the vSphere provider changed how it deals with UUIDs between 1.10 and 1.12(ish). Valid UUIDs are required for the provider to initialize itself and give consistent disk mapping to pods that need persistent volumes.
So, implementation step 1 was to piece together docs from VMware, as well as a few diffs from the good folks at Rancher to get the kube-apiserver and kube-controller-manager to use the vSphere provider.
When the vsphere-integrator is ready (that is, it has been trusted with your credentials), the kubernetes-master charm will generate a cloud-config that looks like this:
[Global] insecure-flag = true datacenters = "<my_datacenter>" vm-uuid = "VMware-<cat /sys/class/dmi/id/product_uuid>" [VirtualCenter "<my_vsphere_ip>"] user = <my_user> password = <my_password> [Workspace] server = <my_vsphere_ip> datacenter = "<my_datacenter>" default-datastore = "datastore1" folder = "kubernetes" resourcepool-path = "" [Disk] scsicontrollertype = "pvscsi"
K8s-master will use that config when starting kube-apiserver and kube-controller-manager, resulting in processes that look like this:
kube-[apiserver|controller-manager] ... --cloud-config=/path/to/cloud-config.conf --cloud-provider=vsphere ...
Step 2 was to get the kubelets on board. This was shockingly simple, once I realized you could set a --provider-id as a kubelet arg. This alters your K8s nodes with a providerID that matches the UUID that the vSphere provider needs. The end result is a node with a ProviderID that looks like this:
kubectl describe no | grep Provider ProviderID: vsphere://<cat /sys/class/dmi/id/product_uuid>
K8s-worker will then set appropriate args so kubelet uses the vSphere cloud provider:
kubelet ... --cloud-provider=vsphere ...
Step 3 was to write all this down and make a PR for the k8s charms. This has been merged, and new K8s charms with this functionality are available in the edge channel. Expect to see these in the stable channel shortly after the K8s 1.12 release.
Takeaway
This post is very specific to K8s/vSphere; if this doesn’t match your use case, I hope you at least have a better understanding of “integrator” charms and how they can help enable cloud-native features in your deployments.
If you did make your way here for K8s/vSphere specifics, rejoice! Deploy vsphere-integrator alongside CDK, and then figure out what to do for the rest of the week since all the heavy lifting is done.
Find me (kwmonroe) on Freenode IRC in #juju if you want to chat more about integrating vSphere with your Juju workloads. Thanks for reading!

What’s the risk of unsolved vulnerabilities in Docker images?
Having a trusted source for your dependencies is critical for a secure software supply chain. How confident are you in your container security? See how Ubuntu and Canonical can help.