In this section we’re going to create some real files to work with. To avoid accidentally trampling over any of your real files, we’re going to start by creating a new directory, well away from your home folder, which will serve as a safer environment in which to experiment:
mkdir /tmp/tutorial
cd /tmp/tutorial
Notice the use of an absolute path, to make sure that we create the tutorial directory inside /tmp. Without the forward slash at the start the mkdir command would try to find a tmp directory inside the current working directory, then try to create a tutorial directory inside that. If it couldn’t find a tmp directory the command would fail.
In case you hadn’t guessed, mkdir is short for ‘make directory’. Now that we’re safely inside our test area (double check with pwd if you’re not certain), let’s create a few subdirectories:
mkdir dir1 dir2 dir3
There’s something a little different about that command. So far we’ve only seen commands that work on their own (cd, pwd) or that have a single item afterwards (cd /, cd ~/Desktop). But this time we’ve added three things after the mkdir command. Those things are referred to as parameters or arguments, and different commands can accept different numbers of arguments. The mkdir command expects at least one argument, whereas the cd command can work with zero or one, but no more. See what happens when you try to pass the wrong number of parameters to a command:
mkdir
cd /etc ~/Desktop
Back to our new directories. The command above will have created three new subdirectories inside our folder. Let’s take a look at them with the ls (list) command:
ls
If you’ve followed the last few commands, your terminal should be looking something like this:
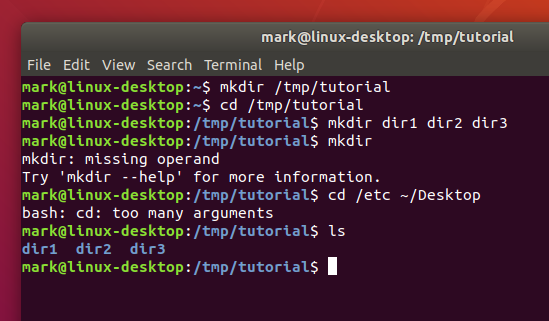
Notice that mkdir created all the folders in one directory. It didn’t create dir3 inside dir2 inside dir1, or any other nested structure. But sometimes it’s handy to be able to do exactly that, and mkdir does have a way:
mkdir -p dir4/dir5/dir6
ls
This time you’ll see that only dir4 has been added to the list, because dir5 is inside it, and dir6 is inside that. Later we’ll install a useful tool to visualise the structure, but you’ve already got enough knowledge to confirm it:
cd dir4
ls
cd dir5
ls
cd ../..
The “-p” that we used is called an option or a switch (in this case it means “create the parent directories, too”). Options are used to modify the way in which a command operates, allowing a single command to behave in a variety of different ways. Unfortunately, due to quirks of history and human nature, options can take different forms in different commands. You’ll often see them as single characters preceded by a hyphen (as in this case), or as longer words preceded by two hyphens. The single character form allows for multiple options to be combined, though not all commands will accept that. And to confuse matters further, some commands don’t clearly identify their options at all, whether or not something is an option is dictated purely by the order of the arguments! You don’t need to worry about all the possibilities, just know that options exist and they can take several different forms. For example the following all mean exactly the same thing:
mkdir --parents --verbose dir4/dir5
mkdir -p --verbose dir4/dir5
mkdir -p -v dir4/dir5
mkdir -pv dir4/dir5
Now we know how to create multiple directories just by passing them as separare arguments to the mkdir command. But suppose we want to create a directory with a space in the name? Let’s give it a go:
mkdir another folder
ls
You probably didn’t even need to type that one in to guess what would happen: two new folders, one called another and the other called folder. If you want to work with spaces in directory or file names, you need to escape them. Don’t worry, nobody’s breaking out of prison; escaping is a computing term that refers to using special codes to tell the computer to treat particular characters differently to normal. Enter the following commands to try out different ways to create folders with spaces in the name:
mkdir "folder 1"
mkdir 'folder 2'
mkdir folder\ 3
mkdir "folder 4" "folder 5"
mkdir -p "folder 6"/"folder 7"
ls
Although the command line can be used to work with files and folders with spaces in their names, the need to escape them with quote marks or backslashes makes things a little more difficult. You can often tell a person who uses the command line a lot just from their file names: they’ll tend to stick to letters and numbers, and use underscores (“_”) or hyphens (“-”) instead of spaces.
Our demonstration folder is starting to look rather full of directories, but is somewhat lacking in files. Let’s remedy that by redirecting the output from a command so that, instead of being printed to the screen, it ends up in a new file. First, remind yourself what the ls command is currently showing:
ls
Suppose we wanted to capture the output of that command as a text file that we can look at or manipulate further. All we need to do is to add the greater-than character (“>”) to the end of our command line, followed by the name of the file to write to:
ls > output.txt
This time there’s nothing printed to the screen, because the output is being redirected to our file instead. If you just run ls on its own you should see that the output.txt file has been created. We can use the cat command to look at its content:
cat output.txt
Okay, so it’s not exactly what was displayed on the screen previously, but it contains all the same data, and it’s in a more useful format for further processing. Let’s look at another command, echo:
echo "This is a test"
Yes, echo just prints its arguments back out again (hence the name). But combine it with a redirect, and you’ve got a way to easily create small test files:
echo "This is a test" > test_1.txt
echo "This is a second test" > test_2.txt
echo "This is a third test" > test_3.txt
ls
You should cat each of these files to check their contents. But cat is more than just a file viewer - its name comes from ‘concatenate’, meaning “to link together”. If you pass more than one filename to cat it will output each of them, one after the other, as a single block of text:
cat test_1.txt test_2.txt test_3.txt
Where you want to pass multiple file names to a single command, there are some useful shortcuts that can save you a lot of typing if the files have similar names. A question mark (“?”) can be used to indicate “any single character” within the file name. An asterisk (“*”) can be used to indicate “zero or more characters”. These are sometimes referred to as “wildcard” characters. A couple of examples might help, the following commands all do the same thing:
cat test_1.txt test_2.txt test_3.txt
cat test_?.txt
cat test_*
More escaping required
As you might have guessed, this capability also means that you need to escape file names with ? or * characters in them, too. It’s usually better to avoid any punctuation in file names if you want to manipulate them from the command line.
If you look at the output of ls you’ll notice that the only files or folders that start with “t” are the three test files we’ve just created, so you could even simplify that last command even further to cat t*, meaning “concatenate all the files whose names start with a t and are followed by zero or more other characters”. Let’s use this capability to join all our files together into a single new file, then view it:
cat t* > combined.txt
cat combined.txt
What do you think will happen if we run those two commands a second time? Will the computer complain, because the file already exists? Will it append the text to the file, so it contains two copies? Or will it replace it entirely? Give it a try to see what happens, but to avoid typing the commands again you can use the Up Arrow and Down Arrow keys to move back and forth through the history of commands you’ve used. Press the Up Arrow a couple of times to get to the first cat and press Enter to run it, then do the same again to get to the second.
As you can see, the file looks the same. That’s not because it’s been left untouched, but because the shell clears out all the content of the file before it writes the output of your cat command into it. Because of this, you should be extra careful when using redirection to make sure that you don’t accidentally overwrite a file you need. If you do want to append to, rather than replace, the content of the files, double up on the greater-than character:
cat t* >> combined.txt
echo "I've appended a line!" >> combined.txt
cat combined.txt
Repeat the first cat a few more times, using the Up Arrow for convenience, and perhaps add a few more arbitrary echo commands, until your text document is so large that it won’t all fit in the terminal at once when you use cat to display it. In order to see the whole file we now need to use a different program, called a pager (because it displays your file one “page” at a time). The standard pager of old was called more, because it puts a line of text at the bottom of each page that says “–More–” to indicate that you haven’t read everything yet. These days there’s a far better pager that you should use instead: because it replaces more, the programmers decided to call it less.
less combined.txt
When viewing a file through less you can use the Up Arrow, Down Arrow, Page Up, Page Down, Home and End keys to move through your file. Give them a try to see the difference between them. When you’ve finished viewing your file, press q to quit less and return to the command line.
Unix systems are case-sensitive, that is, they consider “A.txt” and “a.txt” to be two different files. If you were to run the following lines you would end up with three files:
echo "Lower case" > a.txt
echo "Upper case" > A.TXT
echo "Mixed case" > A.txt
Generally you should try to avoid creating files and folders whose name only varies by case. Not only will it help to avoid confusion, but it will also prevent problems when working with different operating systems. Windows, for example, is case-insensitive, so it would treat all three of the file names above as being a single file, potentially causing data loss or other problems.
You might be tempted to just hit the Caps Lock key and use upper case for all your file names. But the vast majority of shell commands are lower case, so you would end up frequently having to turn it on and off as you type. Most seasoned command line users tend to stick primarily to lower case names for their files and directories so that they rarely have to worry about file name clashes, or which case to use for each letter in the name.
Good naming practice
When you consider both case sensitivity and escaping, a good rule of thumb is to keep your file names all lower case, with only letters, numbers, underscores and hyphens. For files there’s usually also a dot and a few characters on the end to indicate the type of file it is (referred to as the “file extension”). This guideline may seem restrictive, but if you end up using the command line with any frequency you’ll be glad you stuck to this pattern.

%27%20fill%3D%27%23E95420%27%3E%3Cpath%20d%3D%27m15.839%205.293-1.447-2.8a.136.136%200%200%200-.051-.055.144.144%200%200%200-.074-.02h-5.8a.143.143%200%200%200-.091.03.13.13%200%200%200-.034.17.138.138%200%200%200%20.072.06l7.251%202.8a.144.144%200%200%200%20.17-.054.13.13%200%200%200%20.007-.13l-.003-.001ZM11.839%204.945.073.223A.073.073%200%200%200%20.026.221a.07.07%200%200%200-.038.027.065.065%200%200%200%20.007.086l7.962%208.182a.069.069%200%200%200%20.049.022.072.072%200%200%200%20.047-.019l3.805-3.461a.066.066%200%200%200%20.02-.061.065.065%200%200%200-.014-.03.07.07%200%200%200-.028-.02l.003-.002ZM5.382%207.183a.071.071%200%200%200-.062-.022.07.07%200%200%200-.03.011.067.067%200%200%200-.023.025l-4.13%207.696a.065.065%200%200%200-.005.046.068.068%200%200%200%20.027.038.072.072%200%200%200%20.09-.006L7.13%209.18a.066.066%200%200%200%200-.087l-1.75-1.91Z%27%2F%3E%3C%2Fg%3E%3Cdefs%3E%3CclipPath%20id%3D%27a%27%3E%3Cpath%20fill%3D%27%23fff%27%20d%3D%27M0%200h15.83v15.21H0z%27%2F%3E%3C%2FclipPath%3E%3C%2Fdefs%3E%3C%2Fsvg%3E)

%27%20fill%3D%27%23E95420%27%3E%3Cpath%20d%3D%27M1.936%202.592c.668%200%201.21-.515%201.21-1.151S2.604.29%201.936.29C1.267.29.726.805.726%201.44c0%20.637.541%201.152%201.21%201.152ZM14.56.576H3.404a1.587%201.587%200%200%201%20.024%201.69l-.026.04h11.156a.56.56%200%200%200%20.386-.15.518.518%200%200%200%20.16-.369v-.692a.502.502%200%200%200-.16-.369.543.543%200%200%200-.386-.15ZM1.936%206.701c.668%200%201.21-.515%201.21-1.15%200-.637-.542-1.152-1.21-1.152-.669%200-1.21.515-1.21%201.151s.541%201.151%201.21%201.151ZM14.56%204.685H3.404a1.612%201.612%200%200%201%20.242%201.083c-.03.215-.105.421-.219.608l-.026.04h11.157a.56.56%200%200%200%20.386-.15.518.518%200%200%200%20.16-.37v-.692a.5.5%200%200%200-.16-.369.542.542%200%200%200-.386-.15ZM1.936%2010.81c.668%200%201.21-.515%201.21-1.15%200-.637-.542-1.152-1.21-1.152-.669%200-1.21.515-1.21%201.151s.541%201.151%201.21%201.151ZM14.56%208.795H3.404a1.611%201.611%200%200%201%20.243%201.082%201.581%201.581%200%200%201-.245.648h11.156a.559.559%200%200%200%20.386-.15.517.517%200%200%200%20.16-.37v-.692a.502.502%200%200%200-.16-.368.543.543%200%200%200-.386-.15ZM1.936%2014.92c.668%200%201.21-.515%201.21-1.15%200-.637-.542-1.152-1.21-1.152-.669%200-1.21.515-1.21%201.151s.541%201.151%201.21%201.151ZM14.56%2012.904H3.404a1.611%201.611%200%200%201%20.242%201.082%201.58%201.58%200%200%201-.219.608l-.026.04h11.157a.562.562%200%200%200%20.386-.15.517.517%200%200%200%20.16-.37v-.692a.5.5%200%200%200-.16-.369.543.543%200%200%200-.386-.15Z%27%2F%3E%3C%2Fg%3E%3Cdefs%3E%3CclipPath%20id%3D%27a%27%3E%3Cpath%20fill%3D%27%23fff%27%20d%3D%27M0%200h15.83v15.21H0z%27%2F%3E%3C%2FclipPath%3E%3C%2Fdefs%3E%3C%2Fsvg%3E)
%27%20fill%3D%27%23E95420%27%3E%3Cpath%20d%3D%27M9.618.272c-.634%200-1.243.243-1.691.674-.448.43-.7%201.015-.701%201.624v4.221a1.9%201.9%200%200%201%201.362%200v-4.22a.955.955%200%200%201%20.291-.72%201.067%201.067%200%200%201%201.479%200%20.955.955%200%200%201%20.29.719v.962h1.363V2.57c0-.61-.253-1.194-.702-1.625A2.445%202.445%200%200%200%209.618.272ZM9.017%208.433c0%20.21-.065.417-.187.593a1.102%201.102%200%200%201-.499.393c-.203.08-.426.102-.642.06a1.125%201.125%200%200%201-.568-.292%201.055%201.055%200%200%201-.304-.547%201.028%201.028%200%200%201%20.064-.616c.084-.195.226-.362.41-.479a1.143%201.143%200%200%201%201.401.133c.103.1.185.217.24.347.057.129.085.268.085.408ZM2.773%205.855c-.634.001-1.242.244-1.69.674C.633%206.96.381%207.545.38%208.154v4.082a1.901%201.901%200%200%201%201.363%200V8.154a.955.955%200%200%201%20.29-.719%201.067%201.067%200%200%201%201.479%200%20.955.955%200%200%201%20.29.719v.962h1.363v-.962c0-.61-.253-1.194-.702-1.625a2.444%202.444%200%200%200-1.69-.674ZM2.166%2013.878c0%20.21-.065.415-.186.59-.121.174-.294.31-.496.39-.202.08-.424.102-.638.06a1.119%201.119%200%200%201-.565-.29%201.049%201.049%200%200%201-.302-.543c-.043-.206-.02-.42.063-.614.084-.194.225-.36.407-.476a1.136%201.136%200%200%201%201.394.133%201.024%201.024%200%200%201%20.323.75Z%27%2F%3E%3Cpath%20d%3D%27M14.752%204.76a1.789%201.789%200%200%201-.681-.126v2.411a.972.972%200%200%201-.312.682c-.193.179-.45.28-.718.28-.268%200-.526-.101-.718-.28a.972.972%200%200%201-.312-.682V4.32h-1.363v2.726c0%20.61.252%201.195.7%201.626a2.443%202.443%200%200%200%201.692.673c.635%200%201.244-.242%201.692-.673.449-.431.7-1.016.7-1.626v-2.41a1.9%201.9%200%200%201-.68.125ZM15.858%202.822c.037.225%200%20.455-.107.658a1.1%201.1%200%200%201-.49.472%201.161%201.161%200%200%201-1.302-.198%201.04%201.04%200%200%201-.206-1.251%201.1%201.1%200%200%201%20.492-.47%201.161%201.161%200%200%201%201.299.199c.166.16.276.366.314.59ZM7.907%2010.2c-.233%200-.465-.042-.681-.126V12.6a.97.97%200%200%201-.302.7%201.05%201.05%200%200%201-.728.29%201.05%201.05%200%200%201-.728-.29.97.97%200%200%201-.302-.7V9.845H3.804V12.6c0%20.61.252%201.194.7%201.625a2.443%202.443%200%200%200%201.692.674c.634%200%201.243-.243%201.692-.674.448-.43.7-1.015.7-1.625v-2.526a1.887%201.887%200%200%201-.68.127Z%27%2F%3E%3C%2Fg%3E%3Cdefs%3E%3CclipPath%20id%3D%27a%27%3E%3Cpath%20fill%3D%27%23fff%27%20d%3D%27M0%200h15.83v15.21H0z%27%2F%3E%3C%2FclipPath%3E%3C%2Fdefs%3E%3C%2Fsvg%3E)









